状態同期の進化: Aptosで1秒以下の遅延で100k以上のTPSを実現するまでの道のり

「The Evolution of State Sync: The path to 100k+ transactions per second with sub-second latency at Aptos」の翻訳記事です
TL;DR : Aptosブロックチェーンは、分散型ネットワークで高スループット、低遅延、検証済みの状態同期を保証するために、さまざまな新しい技術を活用しています。peerは、今日のAptosで1秒あたり1万トランザクション (TPS)を検証し、1秒未満の遅延で同期することができ、すでに10万以上のTPSに向かって進んでいます。
概要
状態の同期 は重要ですが、ブロックチェーン設計の見落とされがちな観点です。
このブログでは、Aptosでの状態同期の進化について説明し、最新の状態同期プロトコルの設計の背後にあるいくつかの重要な洞察を示します。さらに、状態同期のスループットを10倍に増やし、遅延を3倍に減らし、より高速で効率的なブロックチェーン同期への方法を探ります。
状態同期とは何か?
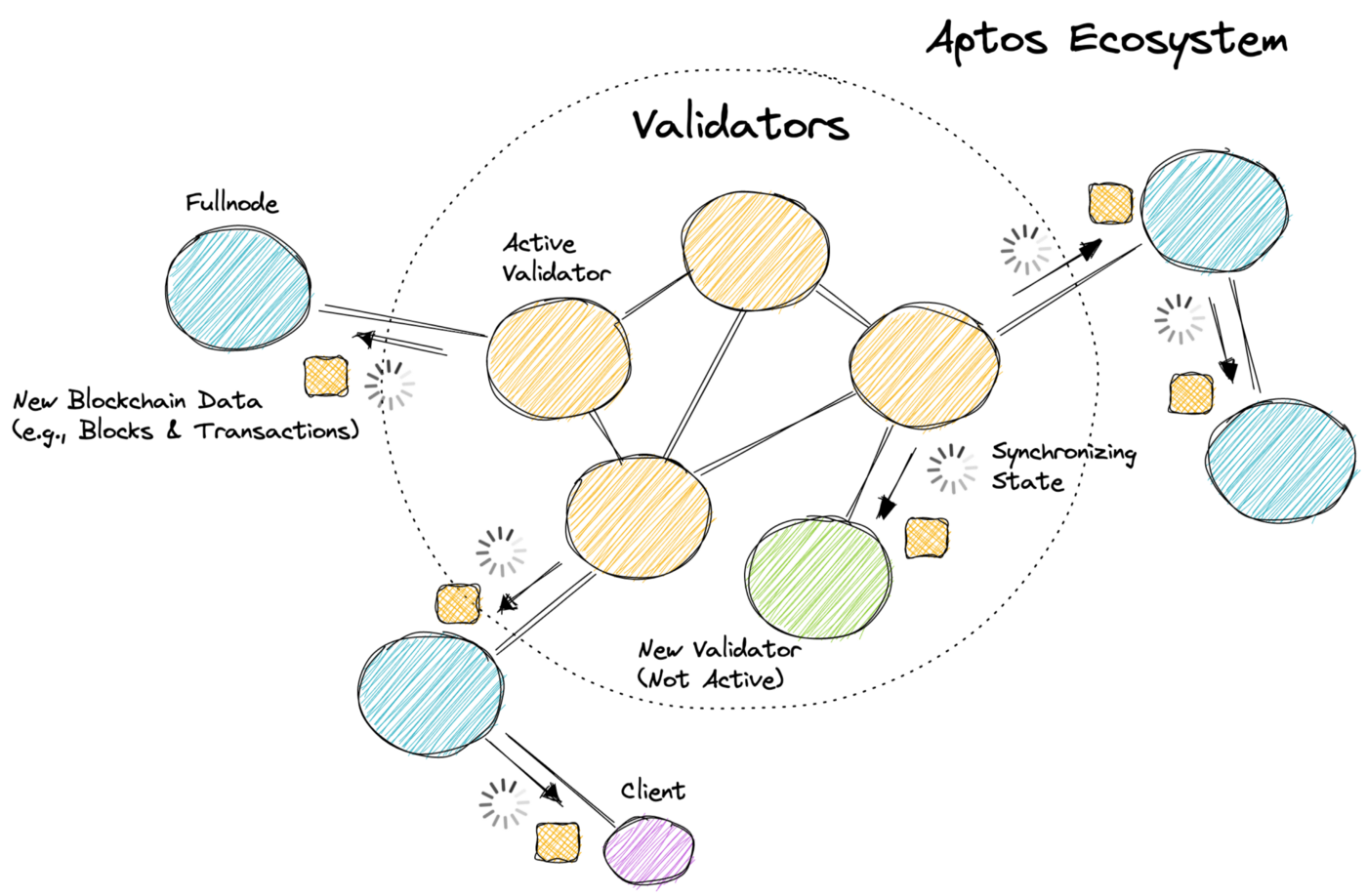
今日のほとんどのブロックチェーンは階層的に構造化されており、ネットワークの中心にアクティブなバリデーターのセットがあります。バリデーターは、トランザクションを実行・ブロックを生成・コンセンサスを達成することによって、ブロックチェーンを成長させます。ブロックチェーンネットワーク内の残りのpeer (フルノードやクライアントなど) は、バリデーターによって生成されたブロックチェーンデータ (ブロックやトランザクションなど) を複製します。状態同期は、非バリデーターpeerがこのブロックチェーンデータを配布・検証・永続化できるようにするプロトコルであり、エコシステム内のすべてのpeerが同期されていることを確認します。これがAptos上でどのように見えるかについて、下の図を参照してください。
なぜ状態同期が重要なのか?
ブロックチェーンを評価するときに状態の同期について言及されることは滅多にありません。多くの場合、より興味深いトピックに特化したホワイトペーパーの脚注です*。ただし状態の同期は、ブロックチェーンのパフォーマンス、セキュリティ、およびユーザーエクスペリエンスに重大な影響を及ぼします。これらのことを考慮してください。
- ファイナライズ (最終確定状態)までの時間とユーザーエクスペリエンス
バリデーターによって新しいトランザクションが実行されると、状態の同期によってデータがpeerとクライアントに伝達されます。
状態の同期が遅い、または信頼性が低い場合には、peerはトランザクション処理の遅延を認識し、人為的にファイナリティまでの時間を長くします。これはユーザーエクスペリエンスに大きな影響を与えます。たとえば、分散型アプリケーション (dApps)、分散型交換 (DEX)、支払い処理はより遅延します。 - コンセンサスとの関係
クラッシュしていたり、残りのバリデーターセットに遅れをとるバリデーターは、状態の同期に依存して速度を回復します (つまり、最新のブロックチェーン状態を同期します)。状態同期がコンセンサスによって実行され、迅速にトランザクションを処理できない場合、クラッシュしたバリデーターは回復できません。さらに、新しいバリデーターはコンセンサスへの参加を開始できなくなり (追いつくことはないため)、フルノードは最新の状態に同期できなくなります (さらに遅れをとることになります!) - 分散化への影響
迅速かつ効率的でスケーラブルな状態同期プロトコルがあれば、次のことが可能になります
(i) バリデータがより自由にコンセンサスに出入りできるため、アクティブなバリデータ セットのローテーションが速くなる
(ii) ネットワーク内でより多くの潜在的バリデータを選択できる
(iii) 長時間待つことなく迅速にオンライン化できるフルノードが増える(iv) 必要リソースが少なく、異種性が増す
これらの要因はすべて、ネットワークにおける分散性を高め、ブロックチェーンのサイズと地理的なスケールを拡大するのに役立ちます。 - データの正確性
状態の同期は、同期中にすべてのブロックチェーンデータの正しさを検証する役割を担っています。これにより、ネットワーク内の悪意のあるpeerや攻撃者がトランザクションデータを変更、検閲、捏造し、それを有効なものとして提示することを防ぐことができます。状態の同期がこれを実行できない場合 (あるいは不正に行った場合)、フルノードやクライアントが騙されて無効なデータを受け入れる可能性があり、ネットワークに壊滅的な影響を与えることになる。
状態同期に関する推論
状態同期をより良く推論するために、まずブロックチェーン実行の一般的なモデルを紹介します。このモデルは特にAptosブロックチェーンを対象としていますが、他のチェーンにも一般化することができます。
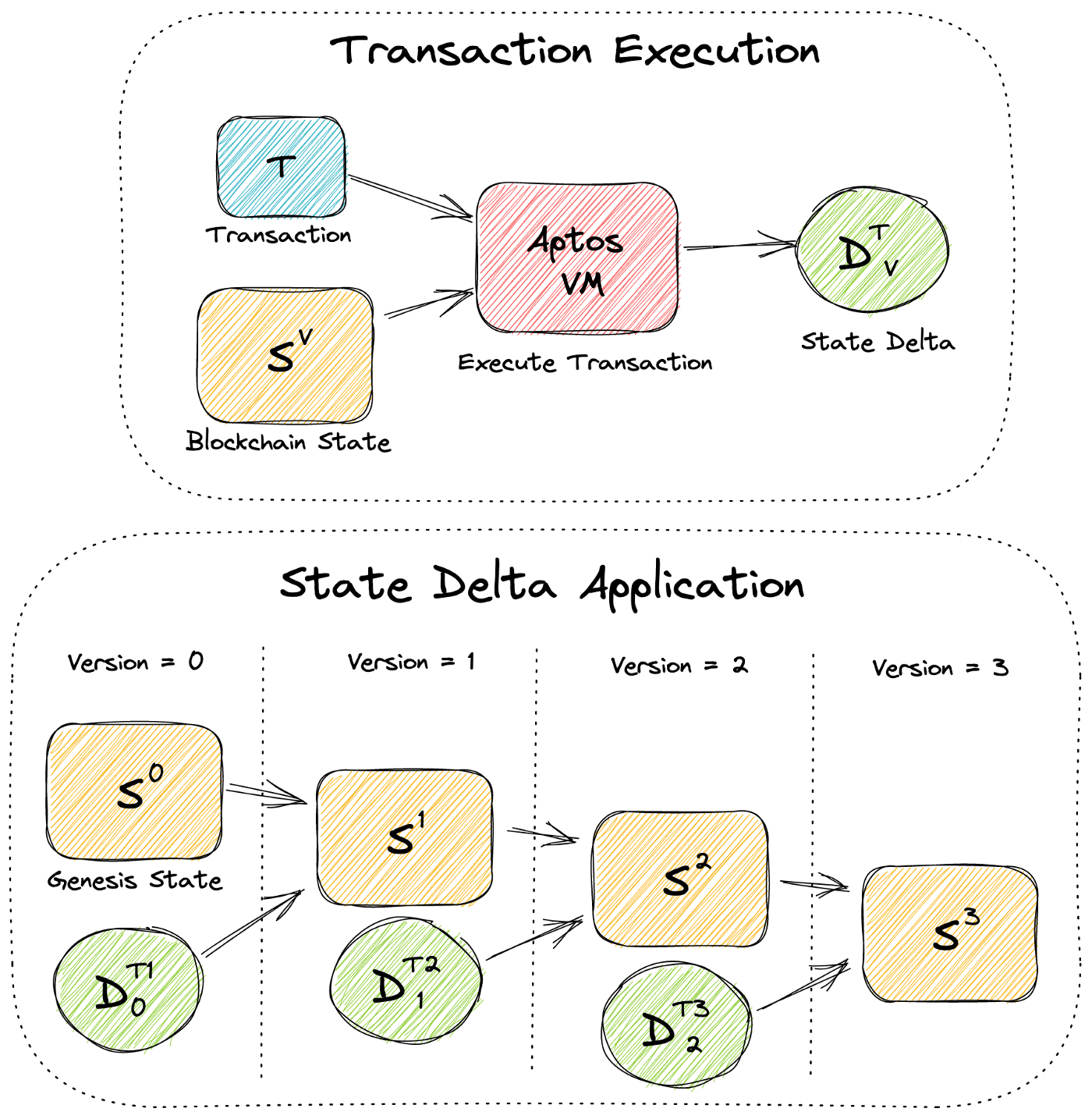
Aptosブロックチェーンを単純なバージョン管理されたデータベースとしてモデル化し、各バージョンVにおいて、すべてのオンチェーンアカウントとリソースを含む一意のブロックチェーン状態Sⱽが存在するようにします。トランザクションTはAptos仮想マシン (VM)によって状態Sⱽで実行され、Tがコミットされた場合にSⱽで発生するすべての状態修正を表す状態差分Dᵥを生成することができるとします。DᵥがSに適用されると (つまり、Tがコミットされると)、新しいバージョンV+1と新しいブロックチェーン状態Sⱽ⁺¹になります。ここでは、一番最初のブロックチェーン状態を初期状態S⁰と呼ぶことにします。以下の図は、トランザクションの実行と状態差分の適用を示しています。
目標は何か ?
一般的なモデルが整ったら、状態同期のいくつかの基本的な目標を定義できます**。
- 高スループット
状態同期では、各peerが1秒あたりに同期できるトランザクションの量を最大化する必要があります。つまり、バリデーターによってコミットされた各Tについて、 SⱽからSⱽ⁺¹への状態遷移の速度を最大化するのです。スループットが低いと、同期時間が長くなりネットワークのボトルネックになります。 - 低遅延
状態同期は、最新のピアがバリデーターによってコミットされた新しいトランザクションを同期するのにかかる時間を最小限に抑える必要があります。つまり、バリデーターによって新たにコミットされたTごとに、SⱽのピアがSⱽ⁺¹に同期するのにかかる時間を最小限に抑えるのです。これは、クライアントが認識するファイナリティまでの全体的な時間に影響します。 - 起動時間の高速化
状態同期は、新しい (またはクラッシュした) peerがブロックチェーンの最新の状態に同期するのにかかる時間を最小にする必要があります。つまり、ピアの現在のバージョンPと状態Sᴾに関係なく、 Sⱽ (ここでVはバリデータによって合意された最も高いデータベースバージョン)に同期するのにかかる時間を最小にすることである。これにより、peerは有用な作業をより迅速に実行できるようになります (例えば、バランスクエリへの応答やトランザクションの検証) - 障害と悪意のあるアクターへの耐性
状態同期は障害 (マシンやネットワークの障害など) に強く、他のpeerを含むネットワーク上の悪意ある行為者にも耐えられる必要があります。これは、トランザクションデータの捏造、ネットワークメッセージの改ざんや再生、日食攻撃など、さまざまな攻撃を克服することを意味します。 - リソースの制約と異質性を許容
状態の同期は、リソース制約 (例 : CPU、メモリ、ストレージ) を許容し、異質性を受け入れる必要があります。分散型ネットワークの性質上、peerは異なる種類のハードウェアにアクセスし、異なる目標に向かって最適化されます。状態同期はこれを考慮する必要があります。
必要な構成要素
次に、状態同期プロトコルを構築するために必要な基本的な構成要素について紹介します。簡潔にするため、各構成要素の概要を以下に示し、技術的な詳細は今後の研究に委ねることにします (各構成要素自体がブログ記事になる可能性もあります ! )。
- 永続ストレージ
マシンのクラッシュや故障があってもデータを持続させるには (そして他のpeerへのデータ配信を可能にするには ! )、各peerが信頼できる永続ストレージにアクセスできる必要があります。Aptosでは現在RocksDBを使用していますが、他のオプションも積極的に検討しています - 検証可能なブロックチェーンデータ
悪意のある人物によるブロックチェーンのデータの改ざんを防ぐため、データが認証され、検証可能であることが必要です。具体的には次のことを証明できる必要があります。
(i) 検証者によって実行されコミットされたすべてのトランザクションT
(ii) 検証者によって実行されコミットされたすべてのトランザクションTの順序
(iii) トランザクションTをコミットした後のブロックチェーンの状態 Sⱽを証明
Aptosでは、次の方法でこれを実現しています。
(i)コミットされた取引とその結果のブロックチェーン状態についてmerkle treesを構築
(ii)バリデータがこれらのmerkle trees Root署名して彼らを認証する - 信頼のルート
Aptosが動的バリデータセット (すなわち、各エポックでのバリデータの変更) をサポートを考えると、peerがAptosブロックチェーンの検証済み履歴から現在のバリデータセットを識別できる必要があります。
(i) 最初のバリデータセットとブロックチェーンの初期状態S⁰を識別するAptosによって認証されたgenesis blob
(ii) 最近の信頼できるwaypoint (例えば、現在のバリデータセットとブロックチェーンの状態S⁰のハッシュ)
genesis blobとwaypointは一緒に、peerに実際のAptosブロックチェーンを同期させ、攻撃 (例えば、long-range attacks) を防ぐことを可能にするroot of trust形成します。
1k TPSの達成 : 素朴なアプローチ
上記のモデルと構成要素を使用して、素朴な状態同期プロトコルを説明しいきます。このプロトコルは、Aptos (つまりstate sync v1) で使用されていた元のプロトコルを単純化したものです。
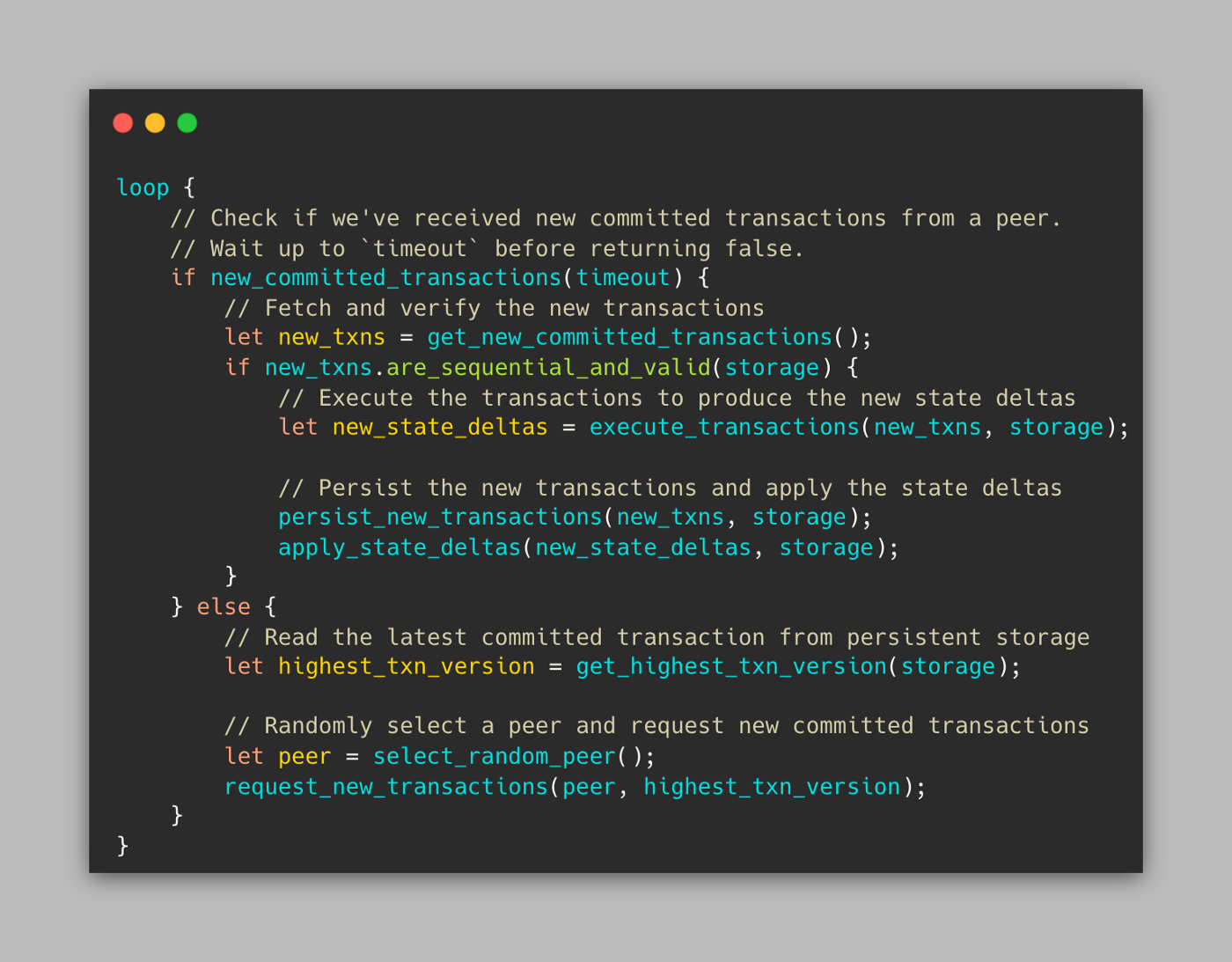
プロトコルは次のように機能します。
(i) Alice(同期peer) は、ローカルで永続化された最高のブロックチェーンバージョンVおよび状態Sⱽを識別します。存在しない場合は、Aliceの初期状態であるS⁰を使用します。
(ii) Aliceの次に、peerであるBobをランダムに選択し、バリデーターによってコミットされた新しいシーケンシャルトランザクションを要求します。
(iii) AliceがBobから応答を受信した場合、新しいトランザクション (T⁰からTᴺ) を検証し、それらを実行して状態差分 (D⁰ᵥからDᵀᵥ₊ₙ)を生成します。
(iv) Aliceはその後、新新しい状態差分を新しい取引とともにストレージに適用し、ブロックチェーンのローカル状態をSⱽからSⱽ⁺¹⁺ᴺに更新します。このループを無期限に繰り返します。プロトコルの擬似コードは次のようになります。
このプロトコルをAptosに実装し、devnetでベンチマークし、解析を行いました。その結果、以下のようなことがわかりました。
- スループットはネットワークレイテンシーに依存する
このプロトコルは最大で1.2k TPSを達成します。しかし、スループットはネットワーク遅延に大きく影響されます。これは、Aliceがデータを順次要求し、peerが応答するのを待つ必要があるためです。devnetの平均的なネットワークラウンドトリップタイム (RTT)が150msであることを考えると、これは最適とは言えません。 - CPUは実行によって支配されます
Aliceが同期のための新しいトランザクションセットを受け取ると、CPUの55%がトランザクションの実行に、40%がデータの検証、ストレージへの状態差分の適用、新しいトランザクションの永続化に費やされることがわかりました。残りの5%は、メッセージ処理、シリアライズ、およびその他のタスクに起因しています。 - 遅延が大きい
ネットワークを最大負荷で走らせたとき、Aliceが新しいトランザクションを受け取るまでの平均待ち時間は、それらがコミットされた後900msです。これは主に、Aliceがデータを要求するときにランダムにピアを選択し、ネットワーク・トポロジーを考慮しないためです。通常バリデータに近いpeerの方がより早く新しいトランザクションを受け取ることができますが、この利点を取り込めていないためです - 起動時間が遅い
上記のプロトコルは、Aliceが生成以降のすべてのトランザクションを再生し、同期することを必要とします。Aliceが最新の状態から大きく遅れている場合、有効になるまでに長い時間待たなければならなリマ戦(これは何時間も、あるいは何日もかかる可能性があります ! ) - パフォーマンスは簡単に操作できる
このプロトコルの性能は、悪意のあるpeerによって大きく影響されます。上記1で確認したように、意図的に遅い(または応答しない)peerはAliceにデータを長い時間を待たせて何もさせません。そのため、同期にかかる時間が大幅に増加します。 - リソース使用率が高い
このプロトコルは、すべてのリソースタイプでコストがかかります。
これは自動的に高いコストとリソース要件を課し、異質性を低下させる。
(i)Aliceはすべてのトランザクションを再実行しなければならないためCPU使用率が高くなります
(ii)Aliceは生成以降のすべてのトランザクションとブロックチェーンの状態を保存しなければならないためストレージ使用率が高くなります
(iii)Aliceは生成以降のすべてのトランザクションをネットワーク経由で受信しなければならないためネットワーク使用率が高くなります - リソースが無駄になっている
Aliceが新しいデータを同期している間、ネットワーク内のpeerもAliceから同期しています。Aliceにデータを要求するpeerの数が増えると、これらの要求を処理するために必要なストレージとCPUに追加の読み取り負荷がかかります。しかし、Aliceがこれらの要求を処理するために実行する計算の多くは、peerが同じデータを要求することが多いため無駄になっています。
10k TPSの達成:最適化されたアプローチ
上記の素朴なプロトコルの試験を受けて、その制限を解決するためにいくつかの修正を加えることができることがわかります。まず、プロトコルを拡張して、2つの同期モードを追加でサポートします。
- 状態差分同期
バリデータがすでにトランザクションを実行し、その結果のブロックチェーン状態をmerkle証明によって証明する際に、peerはバリデータが生成した状態差分を頼りにトランザクションの実行をスキップすることができます。これにより、下記が実現されます
(i) 高い実行コストの回避され、約55%のCPU時間の短縮されます
(ii) Aptos VMの必要性が回避され、差分同期の実装が大幅に簡素化されます
peerは各トランザクションTと状態差分Dᵀᵥをダウンロードし、それらをストレージに適用して新しい状態Sⱽ⁺¹を生成することで同期できるようになります。ただしこの実現には、ネットワーク使用量の増加(約2.5x)という代償を払うことになることに注意してください。 - ブロックチェーンスナップショット同期
バリデーターが各ブロックチェーン状態Sⱽを証明する場合、peerが最新のブロックチェーン状態を (トランザクションや状態差分を使用して生成する代わりに) 直接ダウンロードできるようにすることで、起動時間をさらに短縮することができます。これはブートストラップ時間を大幅に短縮し、Ethereumのスナップ同期に類似したアプローチとなります。トレードオフとして、peerがSⱽ以前のトランザクションやブロックチェーンの状態を保存しなくなります
次に、パフォーマンスとスケーラビリティを向上させるために、多くの一般的な最適化と追加機能を実装します。
- データのプリフェッチ
ネットワーク遅延がスループットに影響するのを防ぐため、データプリフェッチを行うことができます。peerはトランザクションデータ (トランザクションや状態差分など ) を処理する前に他のpeerからプリフェッチし、ネットワーク遅延を削減することができます。 - 実行と保存のパイプライン
同期のスループットをさらに向上させるために、トランザクションの実行とストレージの永続化を分離し、プロセッサ設計でよく使われる最適化であるパイプライン化を使用することができます。これにより、トランザクションT²を実行しながら、トランザクションT¹と状態差分Dᵀをストレージに同時に永続化することができる。 - Peerの監視とレピュテーション
可観測性を向上させ、悪意のあるpeerへの耐性を高めるために、peer監視サービスを実装して次のことができます。
(i) 悪意のある行動 (無効なデータの転送など) がないかpeerを監視する
(ii) peerが持つすべてのトランザクションデータの概要や、バリデーターセットからの認識された距離など、各peerに関するメタデータを特定する
(iii) 各peerのローカルスコアを維持する。この情報は、新しいブロックチェーンデータを要求するときにpeer選択を最適化するために使用できます。 - データキャッシング
ストレージの読み取り負荷を軽減し、同期するピアが増えるにつれて状態同期が冗長な計算を実行しないようにするために、一般的に要求されるデータ項目と応答をメモリに保存するデータキャッシュを実装できます。 - ストレージのプルーニング
時間の経過とともにストレージが継続的に増大するのを防ぐため (たとえば、より多くのトランザクションがコミットされるため)、ピア構成に応じて、不要なトランザクションおよびブロックチェーンデータをストレージから削除する動的プルーナーを実装することもできます(たとえば、数日、週、月より古いものなど)。
我々はこれらの修正を実装し、新しい状態同期プロトコル state sync v2)を作成しました。devnet上でベンチマークを行い、観察しました。
- スループットが5倍から10倍に増加
トランザクションを実行する場合、プロトコルは最大で~4.5k TPSを達成しました。これは主にパイプライン化とデータプリフェッチの結果です (つまり、プロトコルはCPUを完全に飽和させることになります)。状態差分を同期させる場合、プロトコルは10K TPS以上を達成し、さらにトランザクションの実行を回避した結果となっています。いずれの場合も、スループットはネットワーク遅延の影響を受けなくなった。 - 遅延が3分の1に短縮
ネットワークを最大負荷で動作させている間、Aliceが新しいトランザクションを受け取るまでの平均待ち時間は、それらがコミットされた後~300 msであることがわかりました。これは、データのプリフェッチと、より効率的なピア選択によるものです。より反応がよく、バリデータに近いpeerに、より頻繁に連携されるようになりました。 - ブートストラップの大幅に高速化
ブロックチェーンスナップショット同期を使用するpeerは、より迅速にブートストラップすることができます。さらに、ブートストラップ時間はブロックチェーンの長さ (つまりトランザクション数)ではなく、同期するオンチェーンリソースの数に影響されなくなりました。現在devnetでは、peerが数分以内にブートストラップすることができます*** - リソース要件の低減
複数の同期モードとストレージプルーニングにより、必要なリソース要件が低減されました。さらに、peerは同期戦略を柔軟に選択できるため、異質性がサポートされるようになりました。次に例を示します。
(i) CPUに制限のあるpeerはトランザクションの実行をスキップすることができる
(ii) ストレージに制限のあるpeerは積極的にプルーナーを設定することができ
(iii) 迅速に最新情報を取得したいpeerはブロックチェーンのスナップショット同期を実行することができる - リソースのより効率的な使用
peerからの同期要求を処理する際、ストレージの読み取り負荷が大幅に減少し、CPUの浪費も少なくなりました。これは、よく要求されるデータ項目とレスポンスをメモリに保存する新しいデータキャッシュによる成果です。また、 devnetで同期するpeerの数が増えるにつれて、データキャッシュがより効率的になることもわかりました。たとえば、同期するpeer数が20の場合、リクエストごとのキャッシュヒット率は20になります。しかし、peer数が60の場合、キャッシュヒット率は93%-98%になります。ただしこれは、キャッシュを維持するために約150MBのRAMが追加されるという代償を払っています。
100k TPS以上 ?
スループットはすでに10倍、遅延は3倍改善されていますが、まだまだやるべきことがあることに気づきました。
特に、Block-STMを実現し、 Aptosをすべての人にとってレイヤー1にしたい場合は!
では、どうやってそこにたどり着くのでしょうか。私たちはすでに次の状態同期の目標である100k+ TPSに向けて着手しています!詳細は今後のブログ記事で紹介する予定ですが、熱心な読者のためにいくつかのヒントを提供したいと思います。
- トランザクションバッチ処理
現在、Aptosはすべてのトランザクションを検証可能なものとして扱っています。つまり、データの認証と検証に使用されるmerkle証明は、トランザクションの粒度で動作します。このため、検証や保存に非常にコストがかかります。これを回避する一つの方法は、トランザクションのバッチ処理、すなわちトランザクションのバッチ (またはブロック !) に対する証明を実行することである。 - ネットワーク圧縮
ピアツーピアネットワークでは、ネットワークの帯域幅がボトルネックになることがよくありますが、Aptosも例外ではありません。現在、状態同期プリフェッチャーは帯域幅が飽和する前にdevnetで~45K TPSをフェッチすることができます。これは、もし私たちがスケールしたいのであれば問題です。ありがたいことに、peerは非効率なシリアライズ形式を使ってデータを配信していることをすでに認識しており、既製の圧縮を使うことで送信データ量を10x倍以上削減することができます。 - より高速なストレージ書き込み
現在、状態同期のスループットは、ブロックチェーンのデータをストレージに永続化するのにかかる時間がボトルネックになっています。このボトルネックを解消するために、さまざまな最適化・改良を積極的に検討しています
(i) より効率的なデータ構造
(ii) より最適なストレージ構成
(iii) 代替ストレージエンジン - 並列データ処理
データを逐次的に処理する必要がありました (例えば、トランザクションを順次バージョンアップして処理するなど )。しかし、この要件を回避し、並列データ処理を利用してスループットを大幅に向上させることができる既存のアプローチが数多く存在します (例 : ブロックチェーンシャーディング)。
次回まで!
私たちのように、アルゴリズムを設計し、それを実践し、Web3の未来に真のインパクトを与えることに情熱を注いでいる方は、ぜひご連絡ください!Aptosでは採用活動を行っています。
*コンセンサスのように: )
**我々は、状態同期がすべてのオンチェーンリソースの状態を同期する必要があると暗黙のうちに仮定している。部分的な同期戦略 (例えば、特定のアカウントを対象とするライトクライアント) は範囲外であり、将来的に解説していきます。
***この指標は多めに見ておく必要があります。Aptos devnetは隔週で初期化されるため、同期する状態は限定的です。より長く稼働しているネットワーク(例えば、私たちのインセンティブ付きテストネット)でより多くの評価が必要になります。
