Shoal:AptosでBullsharkのレイテンシーを削減する方法
By Balaji Arun and Alexander Spiegelman
Aptosの各コンテンツや、学習材料へはこちらからアクセスできます!

世界トップクラスのエンジニアリングと、Aptosの最先端研究の融合を見てみましょう; Shoal paper
Aptosは、DAG BFTにおける2つの問題を解決し、レイテンシーを大幅に削減するとともに、決定論的実用プロトコルにおけるタイムアウトの必要性を無くすことに成功しました。全体として、Bullsharkのレイテンシを、障害がない場合で40%、障害がある場合で80%改善しました。
Shoalは、Narwhalベースのコンセンサスプロトコル(DAG-Rider、Tusk、Bullsharkなど)をパイプラインとリーダー評価で強化するフレームワークです。パイプラインは、毎ラウンドアンカーを導入することでDAGの順序における待ち時間を短縮して、リーダーレピュテーションは、アンカーが最速の検証者と関連付けられることを保証することでさらに改善します。
さらに、リーダーレピュテーションによって、Shoalは非同期DAG構築を利用して、全てのシナリオでタイムアウトを排除することが可能となります。これによって、ShoalはOptimistic Responsivenessの要素を含む「Prevalent Responsiveness」と呼ばれるプロパティを提供できます。
これらの技術は驚くほどシンプルで、基礎となるプロトコルの複数のインスタンスを次々に実行できます。
動機
ブロックチェーンネットワークの高性能化を追求する中で、通信の複雑さを軽減することに焦点が当てられてきました。しかし、このアプローチは、結果的にスループットの大幅な向上にはつながっていません。例えば、Diemの初期バージョンで実装されたHotstuffは3500 TPSしか達成できず、10万TPS以上を達成するという私たちの目標には大きく及びません。
そしてブレークスルーは、リーダーベースのプロトコルではデータ送信が主要なボトルネックであり、並列化の恩恵を受けられるという認識から生まれています。Narwhalシステムは、データ配信をコアコンセンサスロジックから分離して、全てのバリデータが同時にデータを配信し、コンセンサスコンポーネントはより少ない量のメタデータのみを注文するアーキテクチャを提案しています。Narwhalの論文では、160,000TPSのスループットが報告されています。
以前の記事で、データ発信とコンセンサスを切り離すためのNarwhalの実装であるQuorum Storeと、それを使って現在のコンセンサスプロトコルであるJolteonを拡張する方法について紹介しました。
Jolteonは、Tendermintの線形高速パスとPBFTスタイルのビューチェンジを組み合わせたリーダーベースのプロトコルで、Hotstuffのレイテンシを33%削減することができます。同時に、リーダーベースのコンセンサスプロトコルでは、Narwhalのスループットの可能性を十分に生かしきれないことも明らかになっています。Hotstuff/Jolteonのリーダーは、データ発信とコンセンサスを分離しても、スループットが増加するにつれて制約を受けることになってしまうのです。
そこで、私たちは、通信オーバヘッドゼロのコンセンサスプロトコルであるBullsharkをNarwhal DAG上に配置することにしました。しかし、残念ながら、Bullsharkの高いスループットを可能にするDAG構築は、Jolteonと比較して50%のレイテンシーを伴います。
この記事では、Shoalを紹介するとともに、Bullsharkのレイテンシを劇的に削減する方法を説明します。
DAG-BFTの背景
まず、この記事を理解するための関連する背景を説明します。NarwhalとBullsharkの詳細については、DAG meets BFTの投稿を参照してください。
Narwhal DAGの各ポイントはラウンド番号と関連付けられています。ラウンドrに進むためには、バリデータはまずラウンドr-1に属するn-f個のポイントを取得しなければなりません。各バリデーターはラウンドごとに1つの頂点をブロードキャストすることができ、各ポイントは前のラウンドの頂点を最低n-f個参照します。ネットワークが非同期であるため、バリデータによってDAGのローカルビューが異なることがあります。
以下は、考えられるローカルビューの図です:
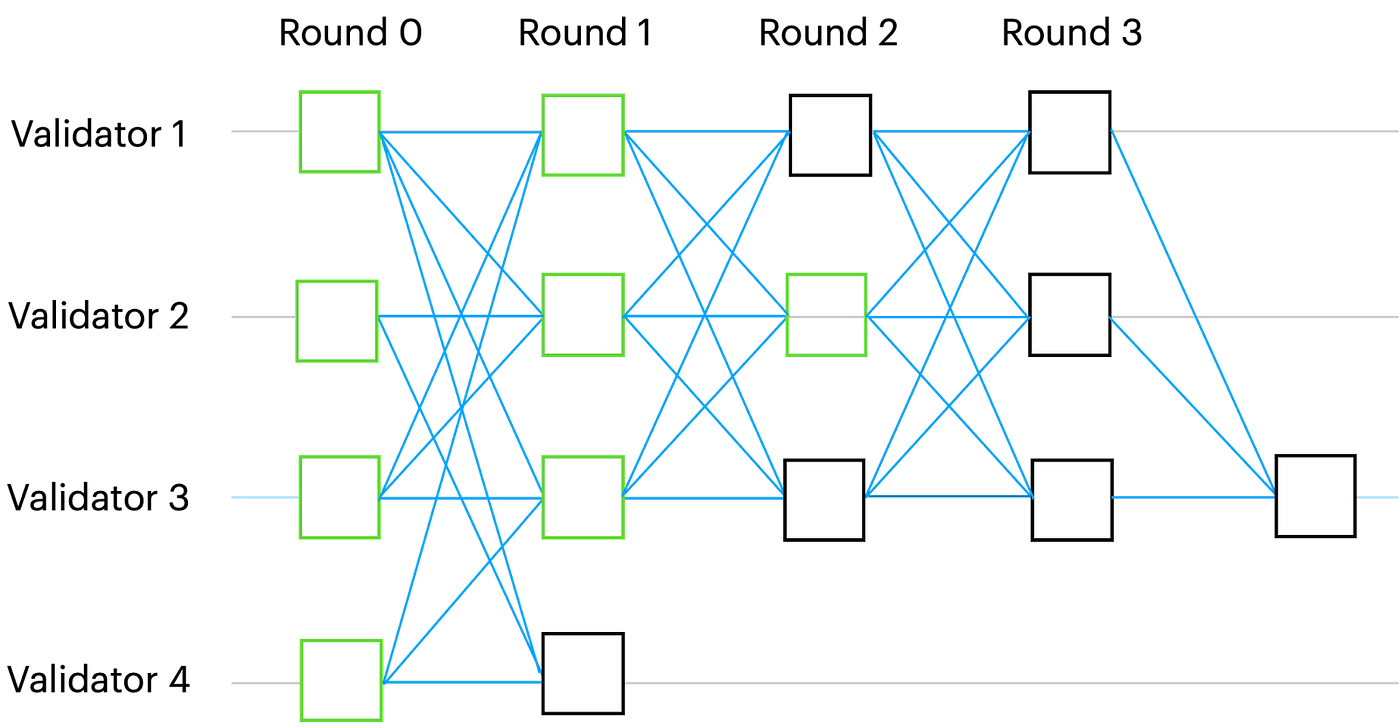
DAGの重要な特性は、非均質性です。2人のバリデータがDAGのローカルビューで同じポイントvを持つ場合、vの因果履歴を全く同じにする性質を持ちます。
全順序
DAGの全ての頂点の順序を、通信のオーバーヘッドなしに合意することが可能となります。そのため、DAG-Rider、Tusk、Bullsharkのバリデータは、DAGの構造を合意プロトコルとして解釈して、頂点は提案を、辺は投票を表します。
DAG構造上の定足数交差ロジックは異なりますが、既存のNarwhalベースのコンセンサスプロトコルはすべて以下の構造を共有しています:
- あらかじめ決められたアンカー数ラウンド(例えば、Bullsharkでは2ラウンド)ごとに、あらかじめ決められたリーダーのいるラウンドがあり、リーダーの頂点はアンカーと呼ばれます。
- アンカーを順番に並べます。バリデータは独立して、決定論的にどのアンカーを注文して、どのアンカーをスキップするかを決定します。
- 因果履歴の順序付けをします。各アンカーについて、決定論的な規則によって、因果履歴の中でそれまで順序が付けられていなかった全ての頂点を順序付けます。
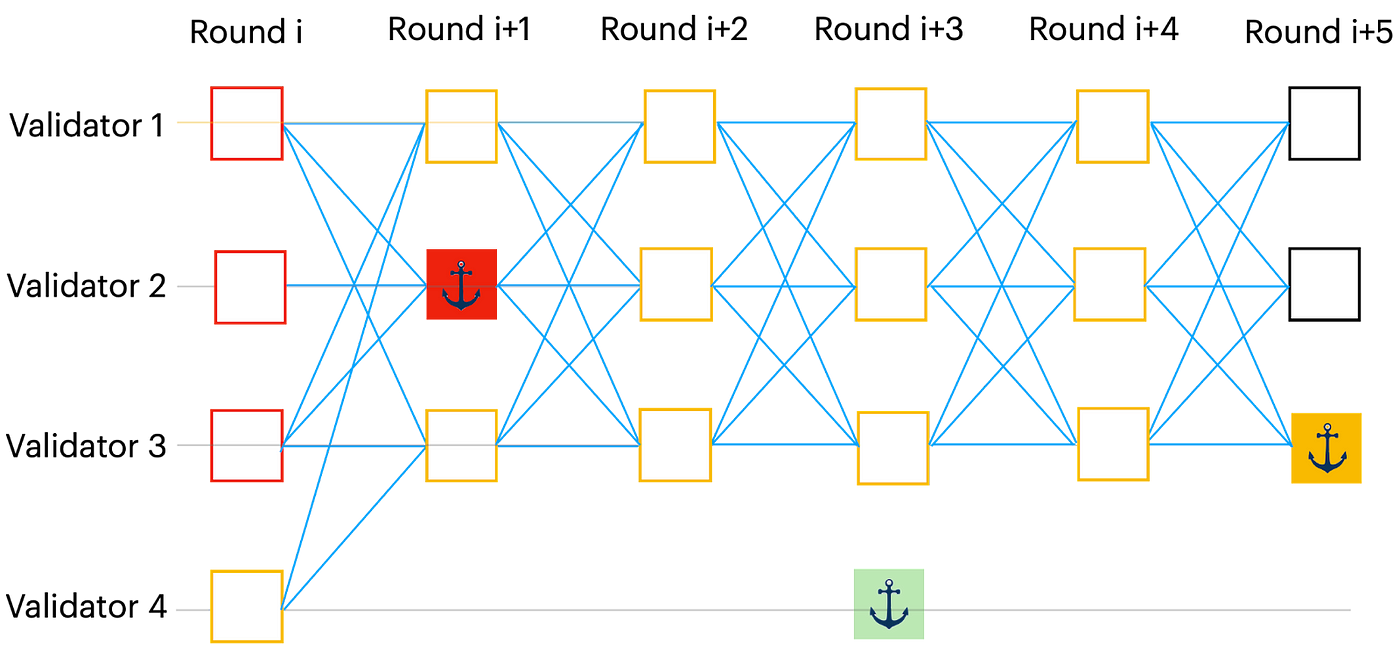
この例では、赤と黄色のアンカーが順序付けされ、緑(DAGに含まれない)はスキップされます。その結果、DAGを順序付けるために、バリデータは決定論的に赤アンカーの因果履歴を最初に、そして黄アンカーの因果履歴を直後に順序付けします。
安全性を満たすための鍵は、上記のステップ(2)で、全ての正直なバリデータが、全てのリストが同じ接頭辞を共有するように、順序付けられたアンカーのリストを作成することを保証することになります。Shoalでは、上記の全てのプロトコルについて、次のような観測を行っています:
全ての検証者は、最初の順序付きアンカーに同意するものとします。
Bullsharkのレイテンシ
Bullsharkの待ち時間は、DAG内の順序付きアンカー間のラウンド数に依存します。Bullsharkの最も実用的な部分同期バージョンは、非同期バージョンよりもレイテンシが良いが、最適とは言い難いものとなります。
問題1:平均ブロックレイテンシ
Bullsharkでは、偶数ラウンドごとにアンカーが存在し、奇数ラウンドごとの頂点は投票として解釈されます。一般的なケースでは、アンカーを注文するために2つのDAGラウンドが必要となります。しかし、アンカーの因果履歴にある頂点は、アンカーが注文されるのを待つために、より多くのラウンドを必要とします。
一般的なケースでは、奇数ラウンドの頂点は3ラウンド、偶数ラウンドのアンカー以外の頂点は4ラウンド必要となります(図3参照)
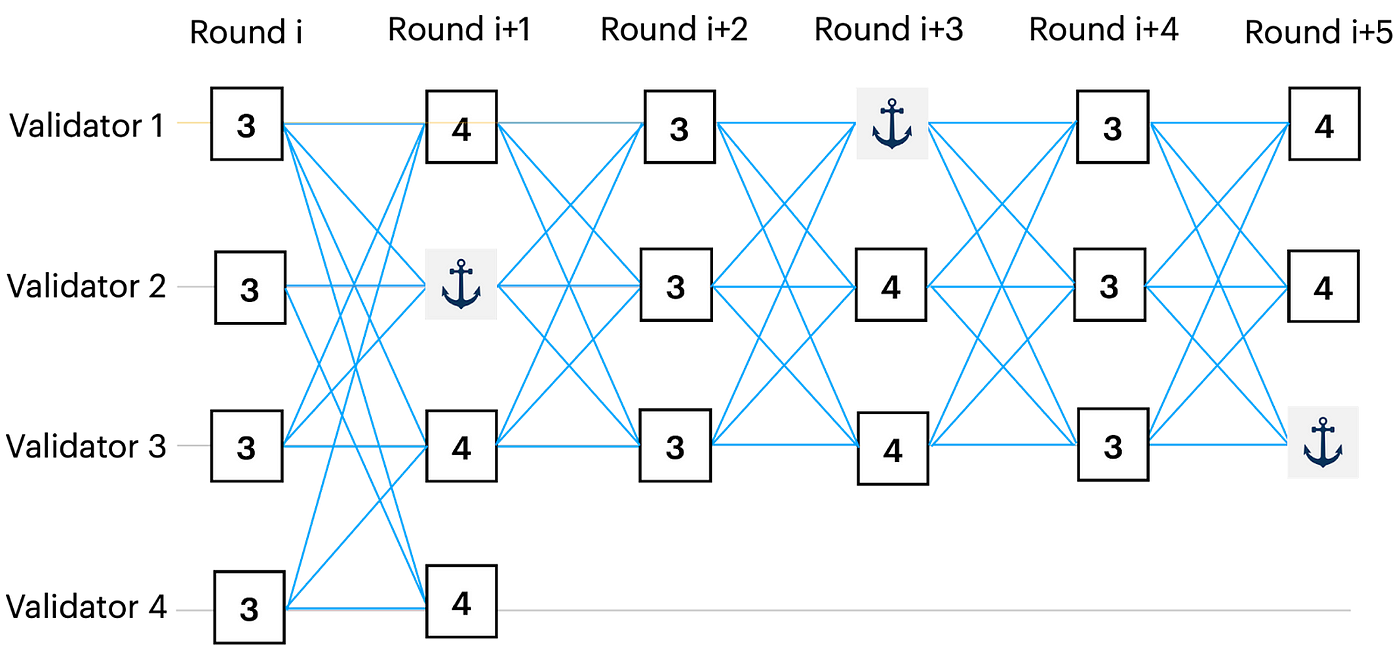
ラウンドiの頂点は同時に注文されるため、その待ち時間は3ラウンドとなります。しかし、ラウンドi+1の頂点は、次のアンカー(ラウンドi+3のアンカー)の注文を待たなければならないので、その注文待ち時間は4ラウンドとなります。
問題2:フェイルケースのレイテンシ
上記のレイテンシ分析は、失敗のないケースに適用されます。一方、ラウンドのリーダーがアンカーを十分に速く放送できなかった場合、そのアンカーはオーダーできない(したがってスキップされる)ので、前のラウンドのすべてのオーダーされていない頂点は、次のアンカーがオーダーされるのを待つ必要があります。特にBullsharkはリーダーを待つためにタイムアウトを使用するため、地理的に複製されたネットワークでは、これは大幅にパフォーマンスを低下させる可能性があります。
Shoalフレームワーク
Shoalは、レイテンシの問題を解決します。Bullshark(または他のNarwhalベースのBFTプロトコル)をパイプラインで強化し、すべてのラウンドでアンカーを可能にし、DAG内のすべての非アンカー頂点の待ち時間を3ラウンドに短縮します。また、Shoalは、DAGにゼロオーバーヘッドリーダー評価メカニズムを導入し、高速リーダーへの選択を偏らせます。
課題
DAGプロトコルの文脈におけるパイプラインとリーダーレピュテーションは、以下の理由から難問と考えられていました:
- これまでのパイプラインの試みは、Bullsharkのコアロジックを変更しようとしたが、これは本質的に不可能であると考えられます。
- DiemBFTで導入され、Carouselで正式化されたリーダーレピュテーションは、バリデータの過去の実績に基づいて将来のリーダー(Bullsharkではアンカー)を動的に選択する考え方です。しかし、Bullsharkでは、リーダーの正体に関する意見の相違は、全く異なる順序付けにつながる可能性があります。このことは、ラウンドアンカーを動的にかつ決定論的に選択することがコンセンサス解決に必要である一方、バリデータは将来のアンカーを選択するために順序付けられた履歴に同意する必要があるという問題の核心につながります。
この問題の難しさを示す証拠として、現在実運用されているものを含めて、Bullsharkの実装のどれもがこれらの機能をサポートしていないことに注目すべきです。
プロトコル
上記のような複雑な課題の解決策は、意外とシンプルさの中に隠されていることが多いものです。
Shoalでは、DAGの局所的な計算を行うことで、以前のラウンドの情報を保存し、再解釈する能力を実現しています。Shoalは、すべての検証者が最初の順序アンカーに同意するという核心的な洞察をもとに、(1)最初の順序アンカーがインスタンスの切り替え点となり、(2)アンカーの因果履歴がリーダーの評判の計算に用いられるように、Bullsharkの複数のインスタンスを順次パイプラインで結合しています。
パイプライン化
Bullsharkと同様に、バリデータはアンカー候補について事前に合意している、つまり、ラウンドをリーダーにマッピングする既知のマッピングF: R -> Vが存在します。ShoalはBullsharkのインスタンスを次々に実行し、各インスタンスでアンカーがマッピングFによって事前に決定されるようになります。また、各インスタンスは1つのアンカーを注文し、それが次のインスタンスへの切り替えのトリガーとなります。
最初に、ShoalはDAGの最初のラウンドでBullsharkの最初のインスタンスを起動し、最初のアンカーが決定されるまで、例えばラウンドrでそれを実行します。したがって、すべてのバリデータは、ラウンドr+1からDAGを再解釈することに決定論的に合意することができることになります。Shoalは、ラウンドr+1でBullsharkの新しいインスタンスを開始するだけです。
最良の場合、これによってShoalはすべてのラウンドでアンカーを注文することができます。最初のラウンドのアンカーは、最初のインスタンスで順序付けされ、Shoalは2ラウンド目に新しいインスタンスを開始し、それ自体がアンカーを持ちます。このアンカーは、そのインスタンスに注文され、別の新しいインスタンスが3ラウンド目にアンカーを注文し、このプロセスが続きます。
図解は下図をご覧ください:
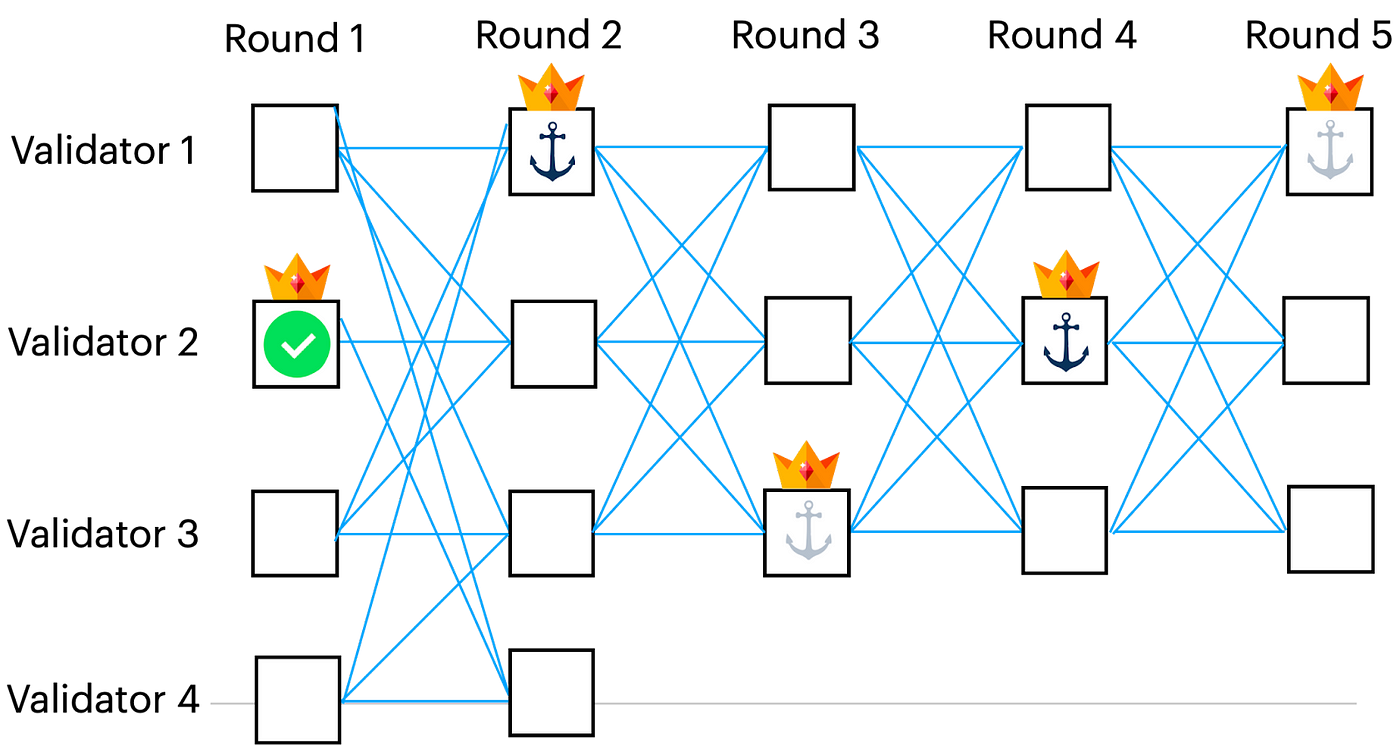
Bullsharkの最初のインスタンスは、ラウンド1、3、5のアンカーを持つDAGを解釈することから始まります。Bullsharkは、緑色のチェックマークで示されたラウンド1のアンカーが、最初のインスタンスで最初に順序付けされたものであると判断します。(一般的なケースでは、このアンカーはスキップされ、他のアンカーが最初に注文される可能性があります)。その後、最初のインスタンスの残りは無視され、Bullsharkの新しいインスタンスが、ラウンド2と4でマークされたアンカーを使用して、ラウンド2から始まる形になります。
リーダーの評価
Bullsharkの順序付けの際にアンカーがスキップされると、レイテンシが増加します。このような場合、前のインスタンスがアンカーを注文するまで新しいインスタンスが開始されないため、パイプライン技術は役に立ちません。Shoalは、各バリデータに最近の活動履歴に基づくスコアを割り当てる評価メカニズムを用いて、対応するリーダーが将来的に選択されにくくなるようにすることで、アンカーを逃した場合に対処します。レスポンスよくプロトコルに参加しているバリデータには、高いスコアが割り当てられる。そうでない場合は、クラッシュしていたり、動作が遅かったり、悪意があったりする可能性があるため、低いスコアが割り当てられることになります。
このアイデアは、スコアが更新されるたびに、ラウンドからリーダーへの事前定義されたマッピングFを決定論的に再計算して、より高いスコアを持つリーダーにバイアスをかけることであります。バリデーターが新しいマッピングに合意するためには、スコア、スコアの導出に使われた履歴に合意する必要があります。
Shoalでは、パイプラインとリーダー評価は、最初の順序付きアンカーに合意した後にDAGを再解釈するという同じコア技術を利用しているため、自然に組み合わせることができます。
実際、唯一の違いは、ラウンドrでアンカーを注文した後、バリデータはラウンドr+1から、ラウンドrで注文されたアンカーの因果履歴に基づいて新しいマッピングF’を計算する必要があるということです。
下図を参照してください:
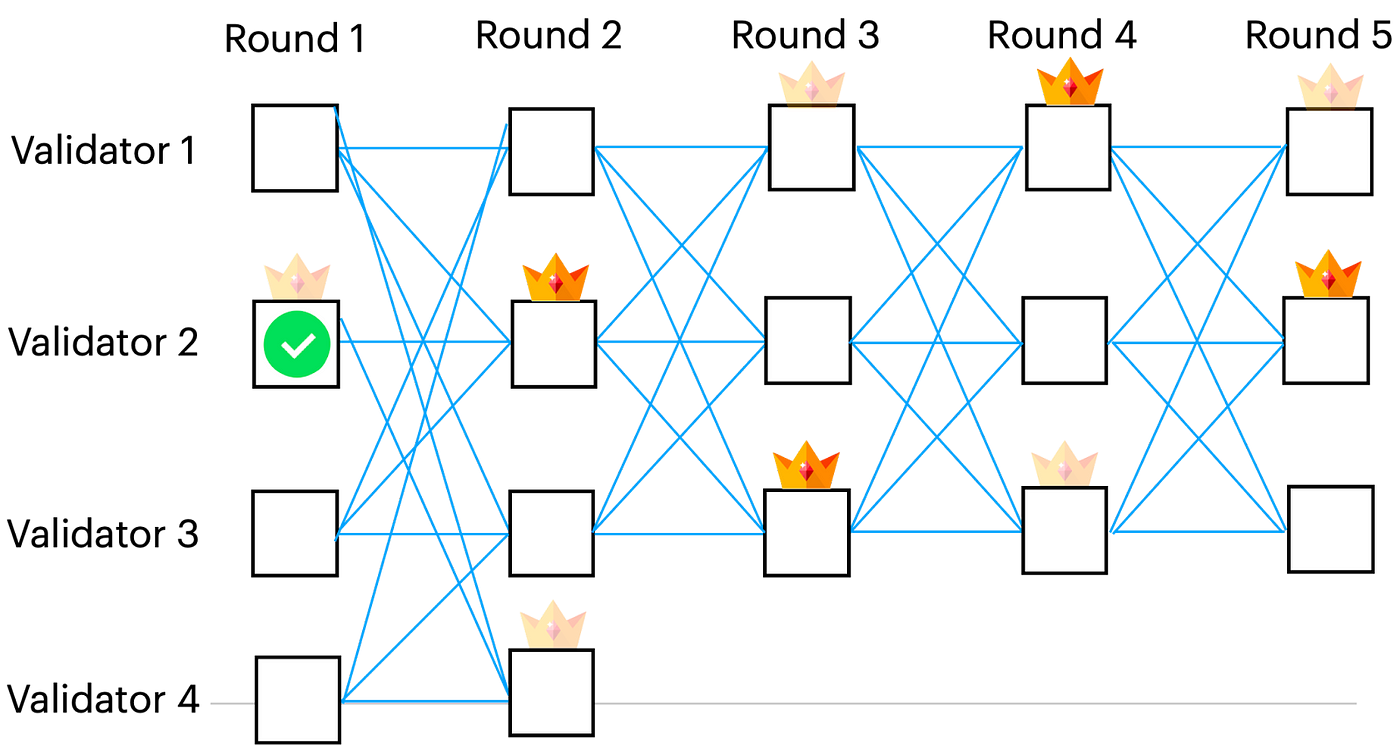
Bullsharkの最初のインスタンスは、ラウンド1でアンカーを注文し、緑のチェックマークでマークされています。その後、アンカーの因果履歴の情報に従って、新しいマッピングF’が計算されます。F’によって決定されたリーダーは、カラフルな👑でマークされています。
タイムアウト不要
タイムアウトは、リーダーベースの決定論的部分同期型BFTの実装において重要な役割を果たしますが、タイムアウトは、管理・観測すべき内部状態の数を増加させる複雑さをもたらします。この複雑さは、デバッグプロセスを複雑にし、より複雑な観測技術を必要となります。
また、タイムアウトを適切に設定することは容易ではなく、環境(ネットワーク)に大きく依存し、動的に調整する必要がある場合が多いため、待ち時間を大幅に増加させます。プロトコルは、故障したリーダーに対して、次のリーダーに移る前にタイムアウトのレイテンシのペナルティを完全に支払う必要があります。したがって、タイムアウトはあまり保守的に設定することはできません。しかし、タイムアウトが短すぎると、プロトコルは良いリーダーを飛ばしてしまうかもしれません。
例えば、負荷が高い場合、Jolteon/Hotstuffのリーダーは圧倒され、進行を促進する前にタイムアウトが切れることが確認されました。
残念ながら、リーダーベースのプロトコル(HotstuffやJolteonなど)は、リーダーが故障するたびにプロトコルの進行を保証するタイムアウトを本質的に必要とします。タイムアウトがなければ、たとえクラッシュしたリーダーであっても、プロトコルを永遠に停止させてしまう可能性があります。非同期では、故障したリーダーと遅いリーダーを区別することは不可能であるため、タイムアウトによって、バリデータはコンセンサスの有効性なしにすべてのリーダーをビューチェンジしてしまうかもしれません。
Bullsharkでは、タイムアウトをDAG構築に利用することで、同期期間中に正直なリーダーがアンカーをDAGに追加する際に、アンカーを順序付けるのに十分な速度で追加することを保証しています。
DAG構築は、ネットワーク速度を推定する「クロック」を提供することが観察されます。タイムアウトがなければ、n-f人の正直な検証者がDAGに頂点を追加し続ける限り、ラウンドは進行し続けます。Bullsharkはネットワーク速度で注文しないかもしれませんが(リーダーが故障しているため)、一部のリーダーが故障していたり、ネットワークが非同期であったりしても、DAGはネットワーク速度で成長し続けることになります。最終的に、故障していないリーダーがアンカーをブロードキャストするのに十分な速度があれば、アンカーの因果関係履歴全体が順序付けられることになります。
私たちの評価では、以下のケースでタイムアウトの有無にかかわらずBullsharkを比較しました:
ファストリーダー:この場合、少なくとも他のバリデータよりも高速であり、アンカーは順序付けられ、タイムアウトは使用されないので、どちらのアプローチも同じ待ち時間を提供することになります。
フェイルリーダー:この場合、タイムアウトを使用しないBullsharkの方が、より優れたレイテンシを提供します。バリデータはそのアンカーをすぐにスキップするためです。
スローリーダー:この場合、タイムアウトがあるBullsharkがより良いパフォーマンスを発揮する唯一のケースとなります。タイムアウトがなければ、リーダーがアンカーを十分に速く放送できないため、アンカーがスキップされる可能性が高いのに対して、タイムアウトがあれば、バリデータはアンカーを待つことになるからです。
Shoalでは、タイムアウトの回避とリーダーの評価は密接に関連しています。遅いリーダーを繰り返し待ち、その結果レイテンシが増大する代わりに、リーダーレピュテーション機構は、遅いバリデータをリーダーとして選択することから排除します。このようにして、システムは高速なバリデータを利用し、あらゆる実世界のシナリオにおいてネットワーク速度で動作することができます。
FLPの不可能性の結果は、どんな決定論的コンセンサスプロトコルもタイムアウトを回避できないことを述べていることに注意が必要です。Shoalはこの結果を回避しなません。全てのアンカーが注文されるのを防ぐことができる理論的な敵対的イベントスケジュールが存在するからです。その代わりに、Shoalは、設定可能な量のアンカーが連続してスキップされた後、タイムアウトに戻ります。実際には、このようなシナリオは極めてまれなものとなります。
一般的な応答性
Hotstuffの論文は、「楽観的な応答性」という概念を広めました。正式には定義されていませんが、直感的には、高速なリーダーや同期ネットワークを含む良いケースにおいて、プロトコルがネットワーク速度で動作できることを意味します。
Shoalは、より厳密には優れた特性を提供し、これをprevalent responsivenessと呼んでいます。具体的には、Hotstuffと比較して、Shoalはリーダーが設定可能な数のラウンドで連続して失敗しても、ネットワークが非同期状態になったとしても、ネットワーク速度で動作し続けます。下の表で、より詳細な比較をご覧ください。
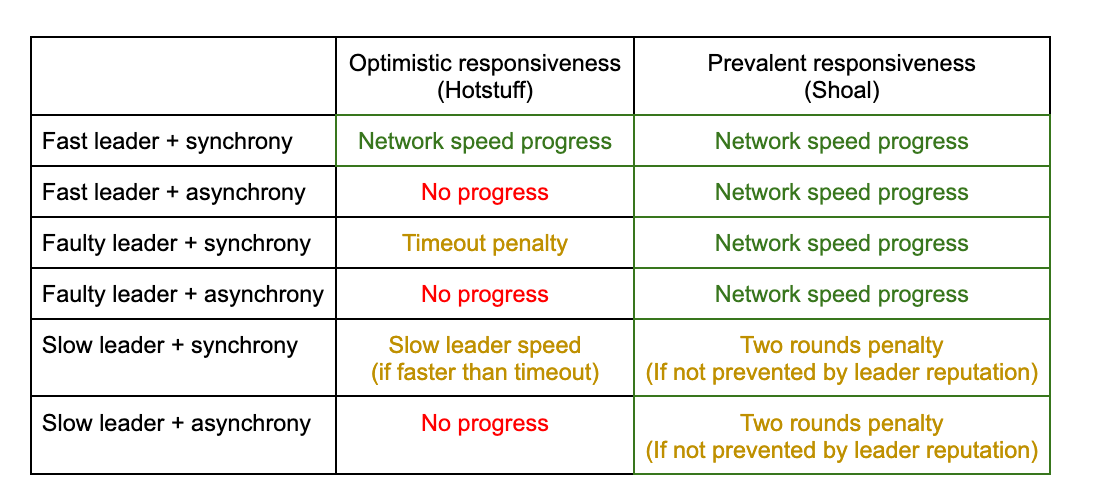
非同期時やリーダーが故障している場合、先行応答性の方が厳密に優れた進捗保証を提供することに注意してください。遅いリーダーとの同期時には、リーダーの遅さに依存するため、その特性は比較になりません。しかし、リーダーの評判が良ければ、遅いリーダーはShoalにほとんど現れません。
評価
BullsharkとShoalは、Narwhalの実装であるQuorum Storeの上に実装されました。Shoal、Bullshark、Jolteonの詳細な比較は、Shoalの論文の評価セクションで見ることができます。ここでは、いくつかのハイライトを紹介します。
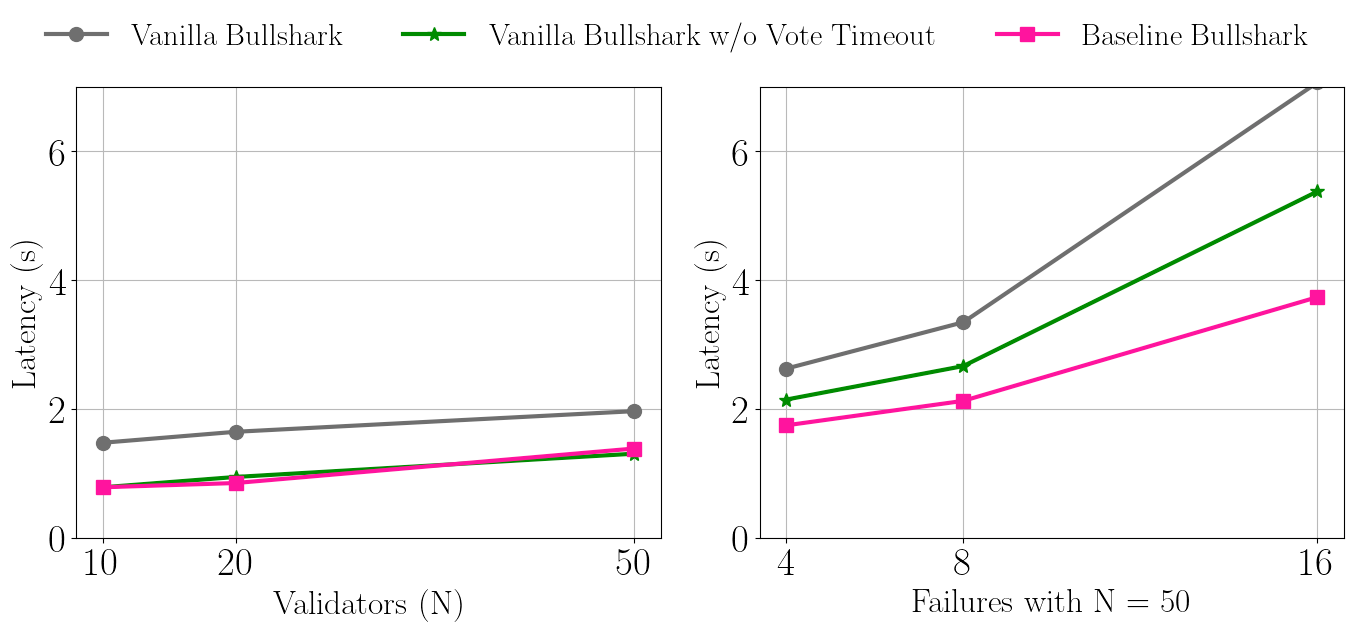
まず、非同期DAG構築の威力を示すために、Bullsharkをタイムアウトあり、なしで比較します。Bullsharkの論文では、非同期ネットワークを想定しているが、高速パスモードが用意されているため、すべてのラウンドでタイムアウトが必要です。このバージョンをVanilla Bullsharkと呼びます。スタンドアロンで部分的に同期ネットワークを仮定したバージョンでは、投票ラウンドでのタイムアウトは不要であることが確認されています。このバージョンをVanilla Bullshark w/o Vote timeoutと呼びます。ベースラインBullsharkは、タイムアウトのないバージョンです。
下の図は、タイムアウトがBullsharkのレイテンシーに与える影響を、失敗の有無で比較したものです。Baseline Bullshark(タイムアウトなし)は、障害が発生した場合に最も優れた性能を発揮します。障害がない場合、Baseline BullsharkはVoteタイムアウトなしのVanilla Bullsharkと同等です。これは、先に述べたように、リーダー評価メカニズムがなければ、優秀だが遅いリーダーの場合、タイムアウトが有利になる可能性があるためです。
次に、ShoalをBaseline Bullshark(タイムアウトなし)でインスタンス化し、パイプラインとリーダー評価メカニズムによるレイテンシの改善を、失敗の有無で実証している。完全性を期すため、障害がない場合のJolteonとの比較も行います。
以下の図7は、障害がない場合を示しています。パイプラインとリーダーレピュテーションの両方が個別にレイテンシーを低減する一方で、それらを組み合わせることで最良のレイテンシーを達成しています。
Jolteonは、データ配信のボトルネックを解消するQuorum Store上で動作するにもかかわらず、バリデータが20個を超えるとスケールしなくなり、Bullshark/Shoalの約半分のスループットしか達成できませんでした。
この結果から、ShoalはBullsharkのレイテンシーを劇的に改善することがわかります。Jolteonについては、コンセンサスレイテンシーのみを測定したことに注意が必要です。JolteonはDAGの上でローカルに実行することができないため、データ配信を切り離すために追加のレイテンシが必要であり、これは測定していません。したがって、高負荷時には、ShoalはJolteonのエンドツーエンドのレイテンシと一致するはずです。
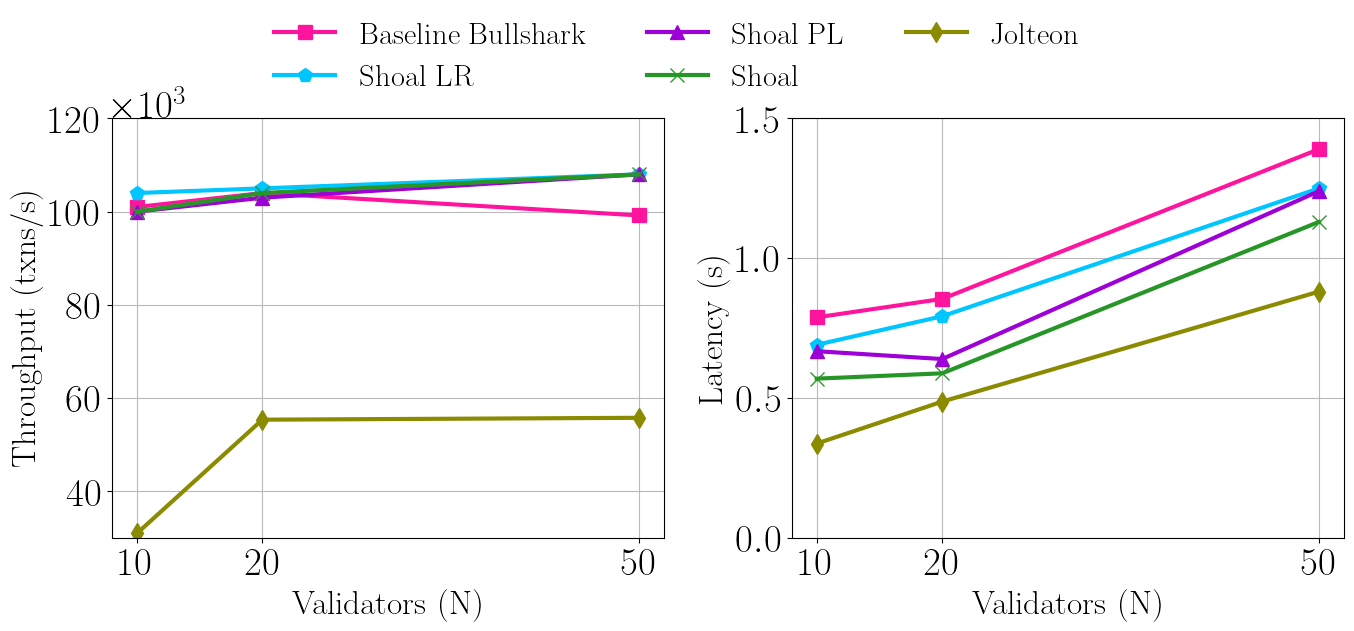
Shoal PLはパイプライン、Shaol LRはリーダーレピュテーションのみをそれぞれサポートしています。
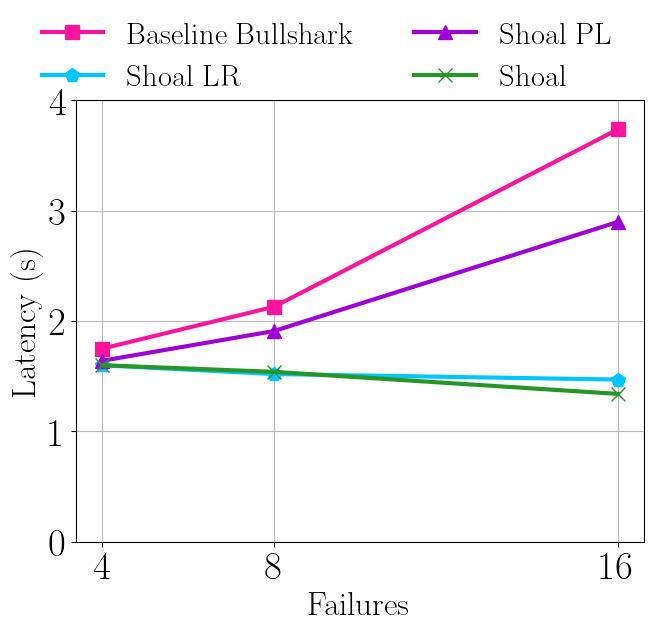
下の図8は、50人の検証者がいる場合の障害ケースで、リーダーレピュテーション機構は、失敗した検証者がリーダーに選ばれる可能性を減らすことで、レイテンシを大幅に改善します。50回中16回の失敗で、ShoalはBaseline Bullsharkより65%低いレイテンシを達成していることに注意が必要です。
世界トップクラスのエンジニアリングとAptosの最先端研究が融合しています。詳細は、Shoalの論文をご参照ください。
