サブグラウンド:データ分析のためのサブグラフ・クエリ
The Graphの各コンテンツをフォローしてご参加ください!

40,000以上のサブグラフがデプロイされ、1000以上のサブグラフがThe Graph Network上ですでに公開されており、The Graphはweb3にとって重要な分散型データプロバイダーとしての地位を確立しています。 サブグラフは、ブロックチェーンデータの標準化されたETLQ(Extract-Transform-Load-Query)レシピであり、The Graph Network上で公開されて、インデクサーによってインデックスが作成されると、ユーザーはGraphQL APIを介して事前にモデリングされたデータをクエリすることができるようになります。Uniswapの分析ダッシュボードからDefiLlamaに至るまで、数え切れないほどのWeb3アプリがThe Graphとサブグラフを利用して、確実かつ効率的にデータを取得しています。
しかし、サブグラフとサブグラフが提供するリッチなデータは、主にフロントエンドのアプリケーションで利用されるように設計されているので、一般的なデータ分析のユースケースには適していません。この投稿では、私たちがどのようにThe Graphの可能性を様々なデータ分析ユースケースに開放しているかを探っていきます。この記事で紹介内容のほとんどは、オープンソースのPythonライブラリSubgroundsで実装されています。
スキーマ・イントロスペクションの活用
RESTのような他のAPI標準とは対照的なGraphQLの最大の利点の1つは、イントロスペクション(API自体の構造のクエリ)がGraphQLに組み込まれていることです。これはGraphQL APIからデータをクエリできるだけでなく、サブグラフで利用可能なすべてのエンティティのリストや、クエリで使用できるフィルタリングパラメータのリストなど、APIに関するメタデータもクエリできることを意味します。
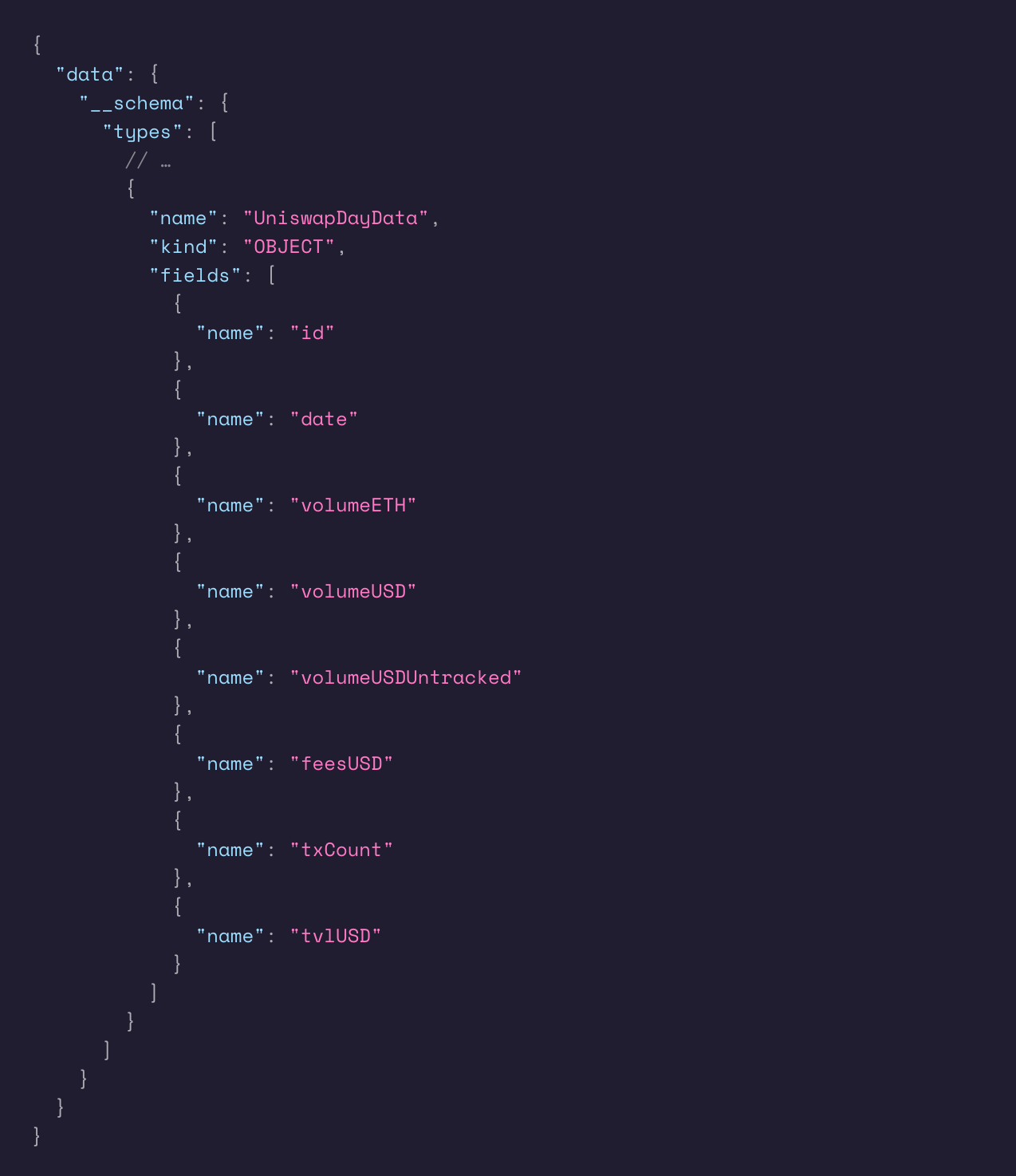
例えば、あるGraphQL APIで定義されているすべての型とそのフィールド(型がObject、つまりエンティティ型の場合)のリストを取得するには、__schemaメタ・フィールドに次のようにクエリします:

Uniswap V3サブグラフでこのクエリを実行すると、以下のメタデータが返されます(注:簡潔にするためUniswapDayData型のメタデータのみ):
GraphQL APIの全メタデータをフェッチする完全なイントロスペクション・クエリは、こちらにあります。(注:同じイントロスペクション・クエリは、サブグラフだけでなく全GraphQL APIに対して機能する)。
GraphQL APIをイントロスペクションすることで、データ分析の目的のために多くの便利な機能がアンロックされますが、ここではそのうちの2つに焦点を当てて、Subgroundsがどのように実装しているかを紹介します: 自動クエリ生成と型チェック/変換です。
クエリの自動生成
サブグラフを利用したフロントエンドアプリケーションを開発する開発者は、目的を達成するために必要なデータとクエリを既にご存知でしょう。これを実現する最善の方法は、可能な限り多くのデータを目的のデータ環境に取り込んで、後者を使ってデータを探索することです。
スキーマ・イントロスペクションを使用することで、利用可能なすべてのサブフィールドをプログラムでGraphQL選択に入力することができ、このプロセスが容易になります。例えば、Uniswap V3のサブグラフにおいて、以下のuniswapDayDatasに関する不完全なクエリがある場合、上記のイントロスペクションクエリの結果を使用して、uniswapDayDatasトップレベルフィールドのすべてのサブフィールドを選択して、このタイプのエンティティに関連するすべての利用可能なデータをクエリできます:

これは、SELECT * FROM uniswapDayDatas SQL クエリに類似しています。
型変換
GraphQLイントロスペクションでは、インテリジェントな型変換を実行することもできます。
ERC-20トークンなどのWeb3アセットでは、非常に大きな小数(18桁が最も一般的)で割り切れることが多く、その結果、通常の32ビット整数では表現できない非常に大きな数値を含むトランザクションが発生します。Subgraphは、BigIntおよびBigDecimal型を使用することで、これらの大きな数値を表現します。BigIntおよびBigDecimal型は、標準のIntおよびFloat型とは異なり、GraphQLを介してクエリされたときに値が文字列として表現されます。
GraphQLのイントロスペクションを使用すると、クエリに対するレスポンスデータ内のどの文字列が実際に数値であり(したがって、クライアント側で適切な型に変換されるべきです)、どの文字列が「本物の」文字列であるかを判別することができます。
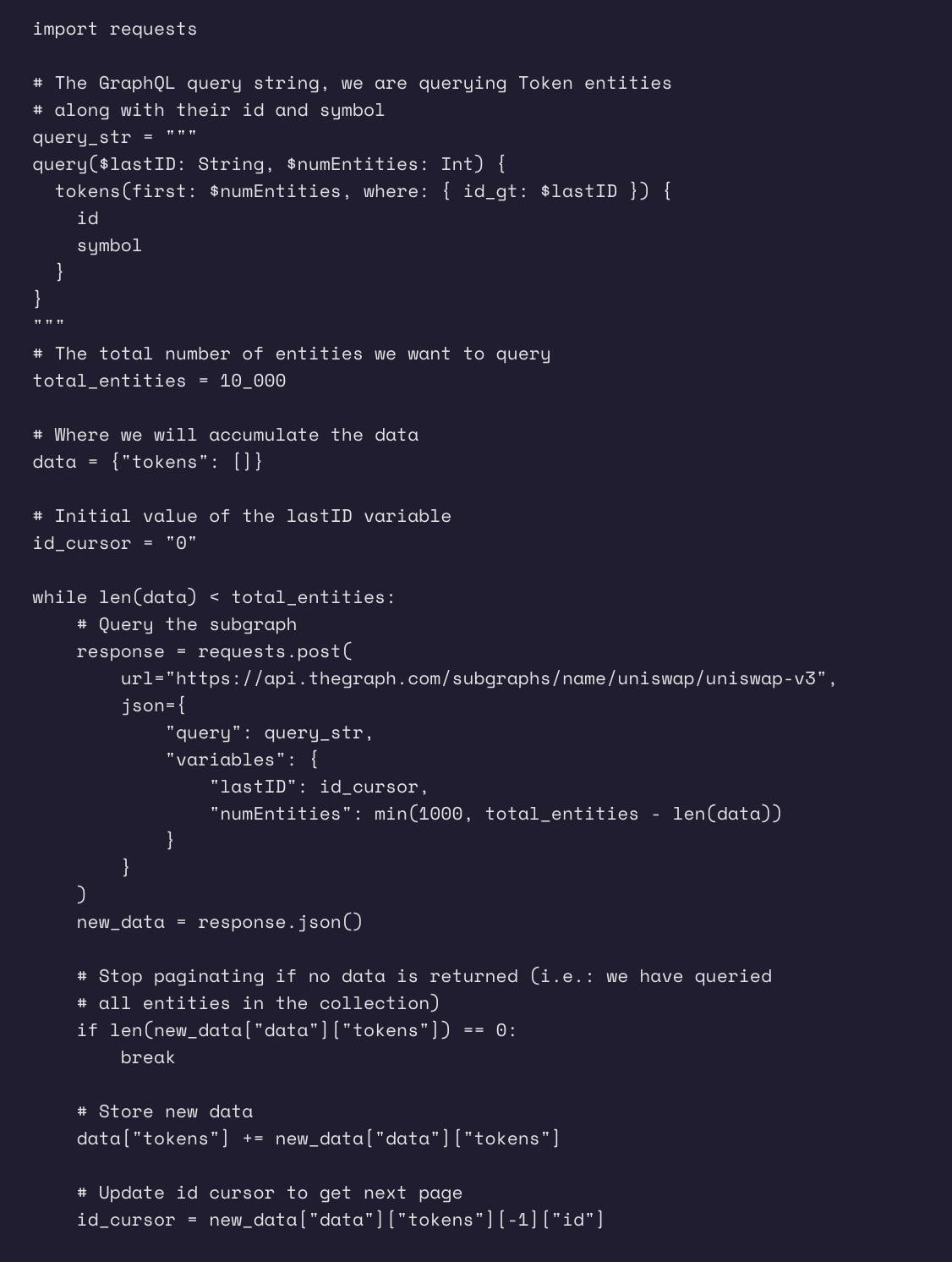
自動ページネーション
サブグラフを扱うデータアナリストの大きな課題は、意味のある分析を構築するために大量のデータをクエリすることです。これは、サブグラフでは1回のクエリで1000エンティティ(行)しかクエリできないためです。ほとんどのフロントエンド・アプリケーションでは、1ページに数個以上のエンティティを表示することはほとんどないため、これは問題にはなりません。しかし、適切なデータ分析を実行するためには、より多くのデータが必要になることが多く、ページ分割が必要になります。
The Graphのドキュメントで示されているように、特定のコレクション内のすべてのエンティティをページ分割する最善の方法は、一意のフィールド(通常はエンティティのID)をカーソルとして使用して、データの後続バッチを取得するためにそのカーソルをインクリメントすることです。 プロセスは以下のようになります:
- クエリするエンティティ数とフィルタ値を変数として設定できるように、一意フィールドにフィルタを設定してクエリを記述します。順序と順序の方向がフィルタと一致していることを確認します(デフォルトでは、エンティティはidの昇順で並べられます。)
- フィルター値を可能な限り小さい値(例えば、idのような文字列フィールドの場合は0)に設定して最初のクエリーを実行します。
- レスポンスデータの中で最大のidを取得し、次のクエリのフィルター値として使用します。
- データが返されなくなるか、必要なエンティティを十分にクエリーできるようになるまで、フィルター値を継続的に更新しながら、ステップ2.と3.を繰り返します。
Graphのドキュメントには、大量のデータをページ分割する方法についての説明はありますが、ページ分割アルゴリズムを実装する方法についての説明はありません。
Pythonでのページネーションメソッドの実装例を示します:
データの平坦化
データ分析を行う場合、データを整理する方法としてテーブルが好まれることが多くあります。テーブルは、JSONデータとは対照的に、行単位の操作(平均、合計、カウントなど)や列単位の操作(投影、変換など)を簡単に実行できます。
サブグラフのクエリ時に返されるデータはJSONで表現されるため、フロントエンド開発の観点からは解析が容易ですが、データ分析の観点、特に高度にネスト化されたデータに対しては作業が困難になります。
1つの解決策は、データを1つ以上のテーブルにフラット化することです。とはいえ、データの平坦化は意見が分かれるところで、必ずしも明確な方法があるわけではありません。例えば、以下のGraphQLクエリと結果のJSONデータ(Uniswap V3サブグラフから)を考えてみましょう:
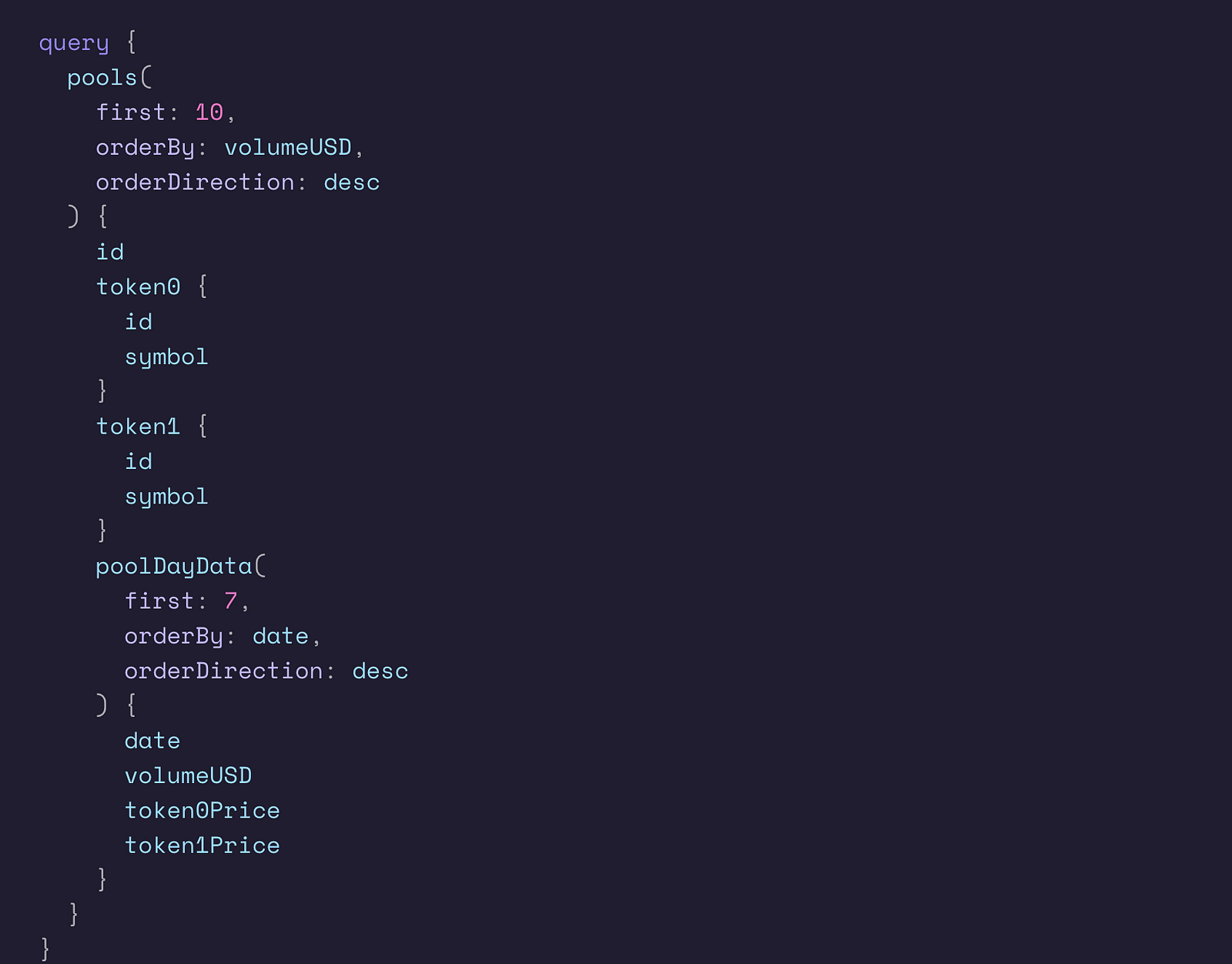
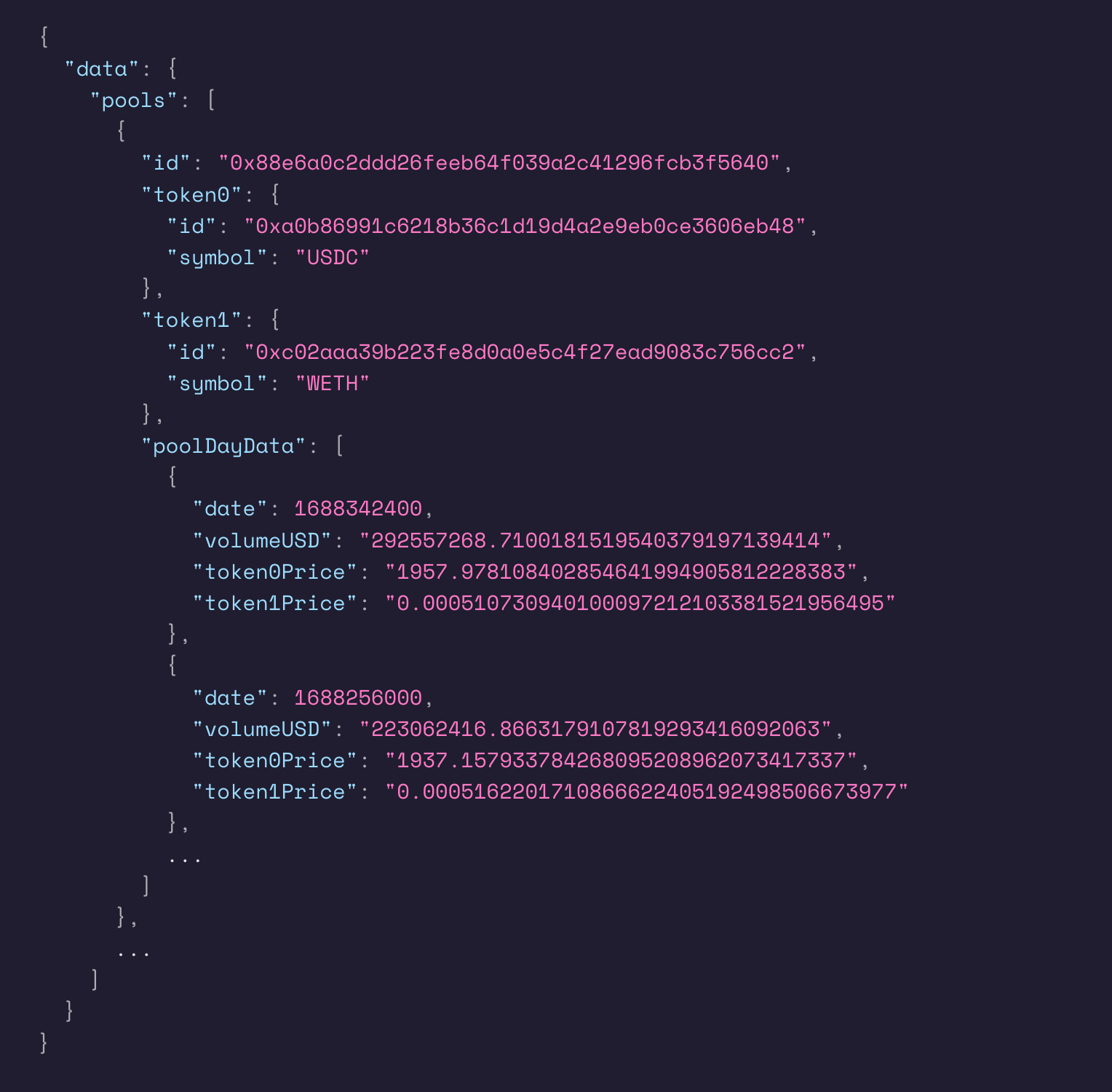
上記のクエリは、出来高上位 10 のリクイディティ・プール、プールのトークンに関する情報、各プールの 1 週間分の価格と出来高のデータをフェッチします。レスポンスデータは高度にネストされているだけでなく、ネストされたリストも含んでいます。データをフラットにする方法は2つあります:
- 2 つのテーブルを作成し、1 つはプール用、もう 1 つは日次データポイント用とする。
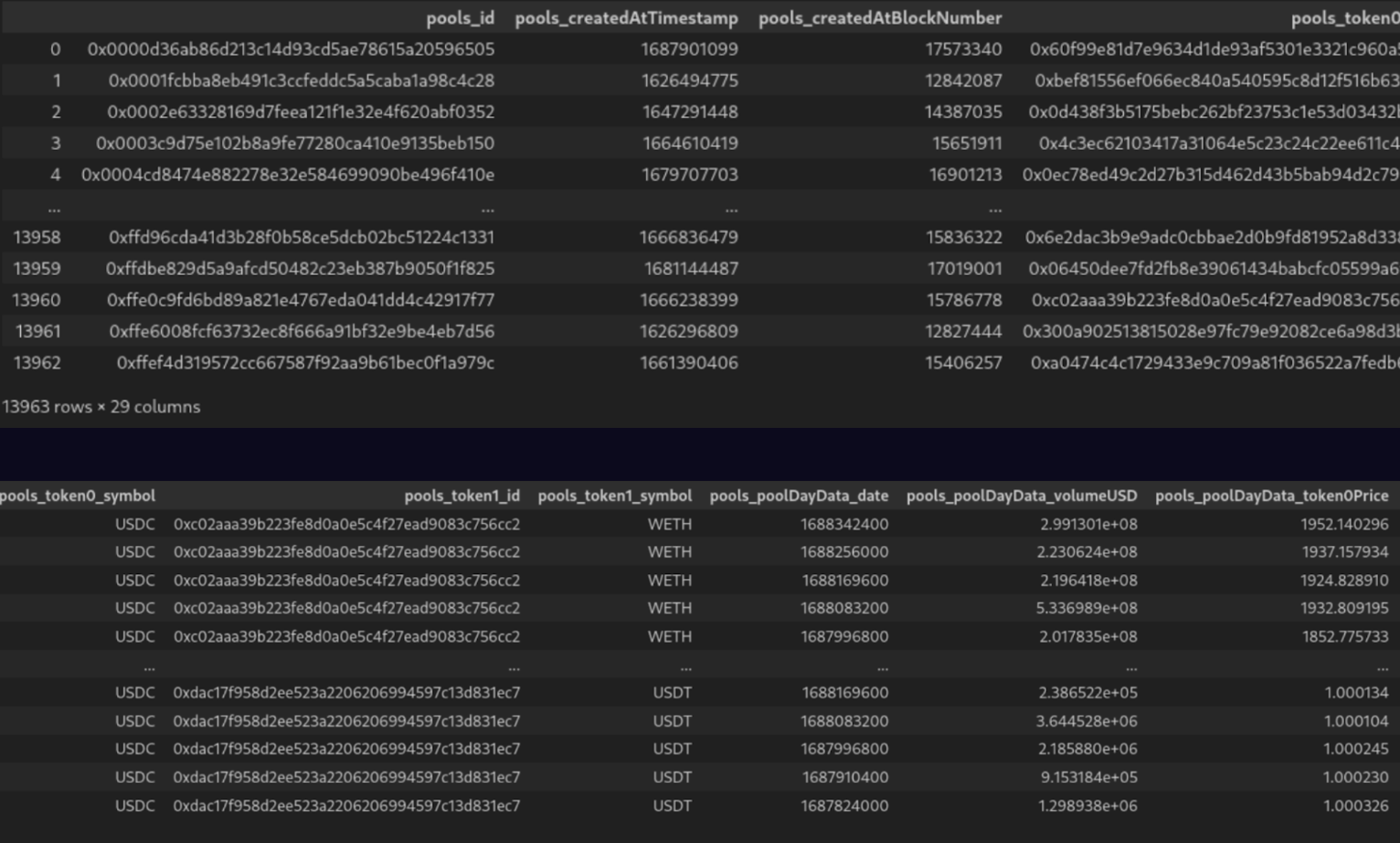
2. 2つのリストを “JOIN “して1つの統一テーブルにし、日次データポイントごとに同じプールデータが繰り返されるようにする。
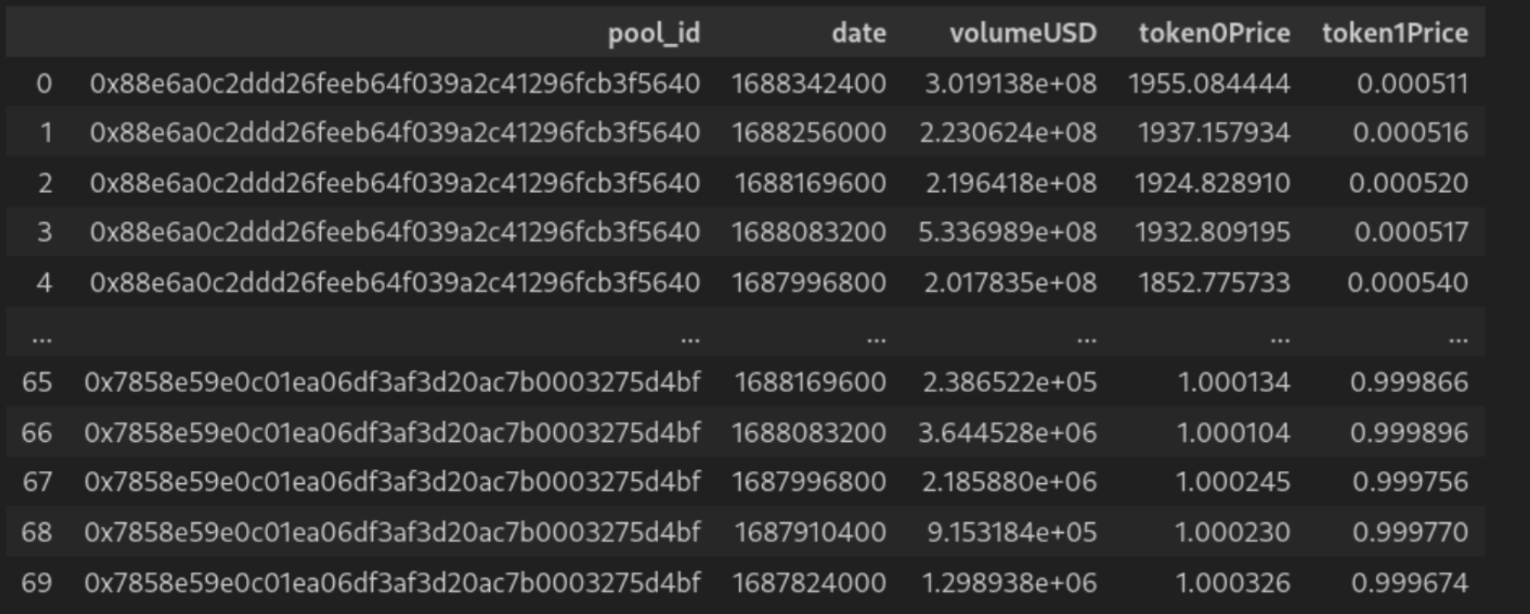
どの平坦化方法を使用するかにかかわらず、データは、生のJSON対応物よりもはるかに分析に適しています。
サブグラウンド: すべてをまとめる
上記のすべてのテクニックは、Subgrounds/Playgrounds Pythonオープンソースライブラリによって活用されていて、データアナリストのためにサブグラフの力を解き放つように設計されています。以下は、Uniswap V3のサブグラフから全てのプール(とその全てのフィールド)を取得し、pandasのデータフレームにダンプするSubgroundsの例です(注:執筆時点でサブグラフ上に約~14,000のプールがあるので、最初の値を15,000に設定すると全てのプールが取得されます)。
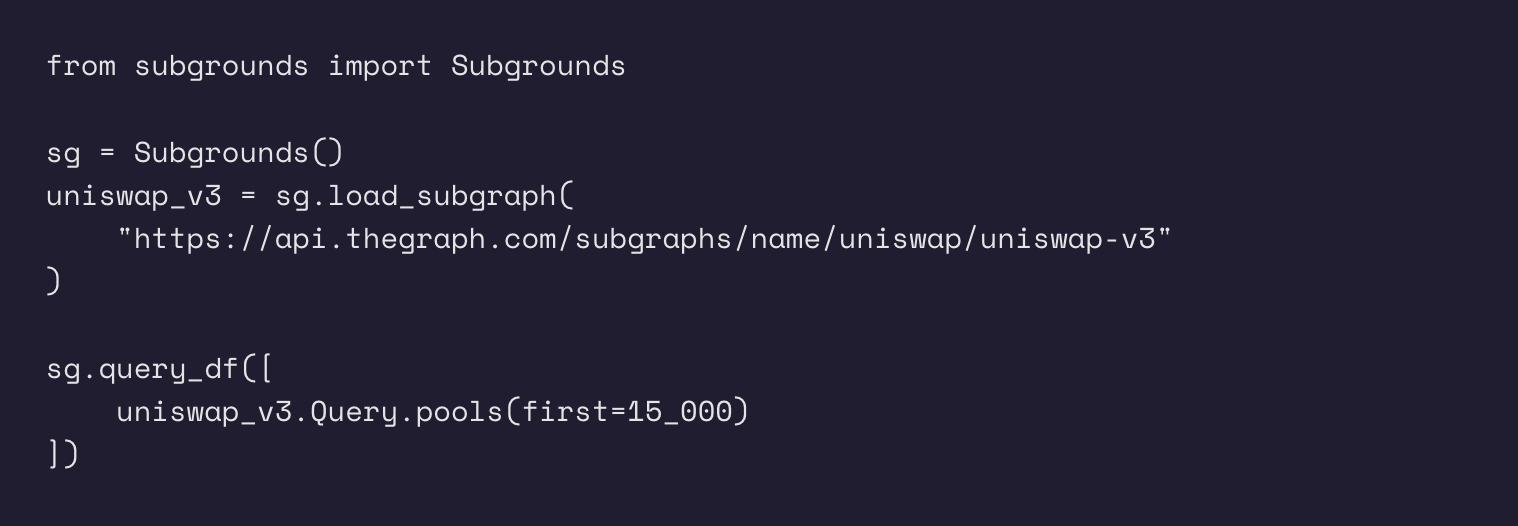
以下は結果のデータフレームのスクリーンショットです:
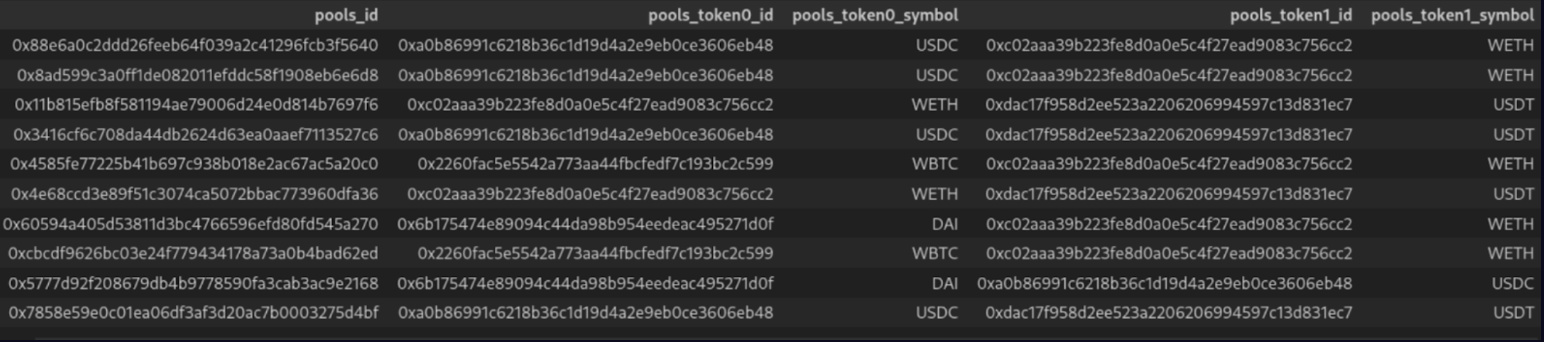
この10行のコードスニペットは、poolsトップレベルフィールドのすべてのサブフィールドを自動的に選択するためのGraphQLスキーマイントロスペクション、最大15,000行のデータを取得するための自動ページ分割、結果をきれいなテーブルにフラット化するためのJSONフラット化、およびBigIntとBigDecimalフィールドがデータフレーム内の数値として終了することを確認するための型変換を活用しています。
現在、すべてのデータがPython環境にダウンロードされ、いよいよ本当の作業である分析が始まります!
まとめ
この投稿では、大規模なデータ分析のためのデータソースとしてThe Graphとサブグラフを使用する際の開発者のエクスペリエンスを向上させるための様々なテクニックを探りました。Subgroundsがどのようにこれらのテクニックを使い、The Graphからデータをクエリして、データ分析用に準備する簡単な方法を提供しているかを見てきました。これは、単なるdAppsにとどまらない、Web3データインフラストラクチャの基盤レイヤーとしてのThe Graphの可能性を示しています。
SubgroundsとPlaygrounds全体についてもっと知りたい方は、ウェブサイトをチェックして、DiscordでThe Graphとweb3データについて話しましょう!
The Graph Builders Blogへの貢献
分散型プロジェクトとして、知識を共有することはエコシステム全体の成長と発展にとって重要であると確信しています。The Graph Builders Blogは、The Graphエコシステムを構築する開発者や関係者が、The Graphを使用した分散型アプリケーションの構築に関する洞察、経験、ベストプラクティスを共有するためのプラットフォームです。
The Graph Builders Blogに貢献することで、あなたの専門知識を披露し、ソリューションを共有し、志を同じくする構築者のコミュニティに触れる機会を得ることができます。私たちは、あなたの洞察が他の人々を刺激し、教育し、完全に分散化された未来のビジョンに貢献することを確信しています。
The Graph Builders Blogの著者になる特典
- The Graphの編集者があなたのブログを承認すると、The Graphのサイトで紹介され、数十万人の読者にリーチできます。
- 約30万人のTwitterフォロワーを含むソーシャルメディアへの投稿で、あなたをハイライトし、タグ付けします。
- The Graph Buildersブログ作者」POAPを差し上げます。
- LinkedInや履歴書にThe Graph Builders Blogの著者を追加することができます。
The Graph Builders Blogへの寄稿をご希望の方は、こちらにご記入ください。
The Graphについて
The Graphは、web3のインデックスとクエリーのレイヤーです。 開発者はサブグラフと呼ばれるオープンAPIを構築・公開し、アプリケーションはGraphQLを使用してクエリを実行することができます。
The Graphは現在、Ethereum, NEAR, Arbitrum, Optimism, Polygon, Avalanche, Celo, Fantom, Moonbeam, IPFS, PoAなど40種類のネットワークからのインデックスデータをサポートしており、さらに多くのネットワークが近日中に登場する予定です。現在までに、88,900以上のサブグラフがホスティングサービス上に展開されています。
グラフネットワークの開発者向けセルフサービス体験を2021年7月にローンチして以来、800以上のサブグラフがネットワークに移行し、450以上のインデクサーがサブグラフのクエリを提供し、11,300以上のデリゲーター、2,500以上のキュレーターが参加しています。
Web3アプリケーションを構築している開発者であれば、ブロックチェーンからのデータのインデックシングやクエリにサブグラフを利用することができます。The Graphによって、高い効率性とパフォーマンスによるUIデータ表示が可能になり、他の開発者もあなたのサブグラフを使用することができます。また、Subgraph Studioを使ってネットワークにサブグラフをデプロイしたり、Graph Explorerにある既存サブグラフをクエリすることができます。
The Graph Foundationは、The Graph Networkを統括しており、同時にThe Graph Foundationは、Technical Councilによって統括されています。Edge & Node、StreamingFast、Semiotic Labs、The Guild、Messari、GraphOpsが、The Graphエコシステム内の外部組織として貢献参加しています。
The Graphの各コンテンツをフォローしてご参加ください!