ブロックチェーン上でのDIDアグリゲーターの開発 (part2)
Litentryプロトコルの技術アーキテクチャ
著:Litentry

概要
Litentry Networkは、プライバシーを第一に考えた分散型のIDアグリゲーション・コンピューティング・サービスを提供しています。Litentry Networkは、ブロックチェーンコンセンサスレイヤーの複雑さを排除し、マルチネットワークIDアグリゲーションのためのフォーマットにとらわれないDIDデータの計算を行います。IDアグリゲーションレイヤーは、分散型アプリケーションが信頼性の高いID関連データやクレジット関連データを取得することを可能にするものです。
IDアグリゲーションサービスは、担保融資、DeFiでの保険料率計算、DAOガバナンスにおける議決権計算、KYCサービスでの認証プロセス(BOTのAirdropやIDOからの防止)などに利用できます。
Litentry Networkは、Chainlinkのようなブロックチェーンオラクルとは異なり、高レベルのデータを計算するコンピューティングレイヤーを追加しています。現在、Litentryは主にID関連のデータ計算に使用されていますが、このアーキテクチャはあらゆる種類の高レベルのデータ計算要求を解決できる可能性を秘めています。
用語解説
分散型アイデンティティ・アグリゲーション
異なるプラットフォームやブロックチェーン上の同一人物の異なるアカウントやIDデータを分散的に集約することであり、Litentryは世界初となる分散型IDアグリゲーションサービスを提供します。パブリックブロックチェーンによる分散化を用いてDIDデータの整合性と信頼性を確保します。
データレジストリ
使用する特定の技術にかかわらず、ユーザーのアイデンティティを記録し、ユーザーのアイデンティティ情報を得るために必要なデータを返すことをサポートするシステムはデータレジストリと呼ばれます。例としては、分散型台帳や分散型ファイルシステム、あらゆる種類のデータベース、ピアツーピアネットワークなどがあります。
WASMスマートコントラクト
WebAssemblyのコンパイルは現代の幅広いプログラミング言語を対象としています。スマートコントラクトのフォーマットとしてWebAssemblyを使用するメリットはこちらをご覧ください。開発者は、カスタマイズ可能なIDスコアリングアルゴリズムやID関連イベントを作成することが可能になります。
オフチェーンTEEワーカー(OCTW)
オフチェーン・ワーカー(OCW)は、Substrateノードが、計算に時間がかかりすぎたり、CPUやメモリのリソースが多すぎたり、結果が非決定的であったりするタスクをオフロードすることができます。具体的には、HTTPリクエストの取得やJSONの解析を可能にするヘルパー群があります。また、ネットワーク上で共有されない特定のSubstrateノード専用のストレージも提供し、オフチェーン・ワーカーは、署名付きまたは署名なしのトランザクションをオンチェーンに戻すこともできます。OCTWとは、TEE(Trusted Execution Environment)に実装されたOCWのことです。
検証可能なクレデンシャル
W3C Verifiable Credentials 仕様[VC-DATA-MODEL]で定義された、暗号的に検証可能なデジ タル・クレデンシャルの標準データ・モデルおよび表現形式のこと。
識別方法
Litentryにおける識別方法(Identification Method)の定義は、識別できないデータを人間が読めるIDデータに変えるために使用する一般的な方法を指します。例えば、クレジットスコアやシンボルバッジのようなものです。Litentry Networkでは、設定可能な関数を使用してIDデータを計算しますが、これには2種類の識別方法が含まれます 。
識別イベント
識別イベント(Identification Events)とは、ターゲティングデータに基づいて、特定のユーザーの行動を分析し、ID関連情報を出力するようにデータ分析装置に指示する計算コマンドです。
ID スコアリング・アルゴリズム
IDスコアリングアルゴリズムは、IDスコアの計算に使用されます。これは、要求された ID データの各部分の重み付け式を指定するものです。IDスコアリング・アルゴリズムは、WASMスマートコントラクトを介して公開記録され、異なるリクエスターによって再利用することができます。
アーキテクチャ
主に3つの異なるレイヤーを含んでいます:
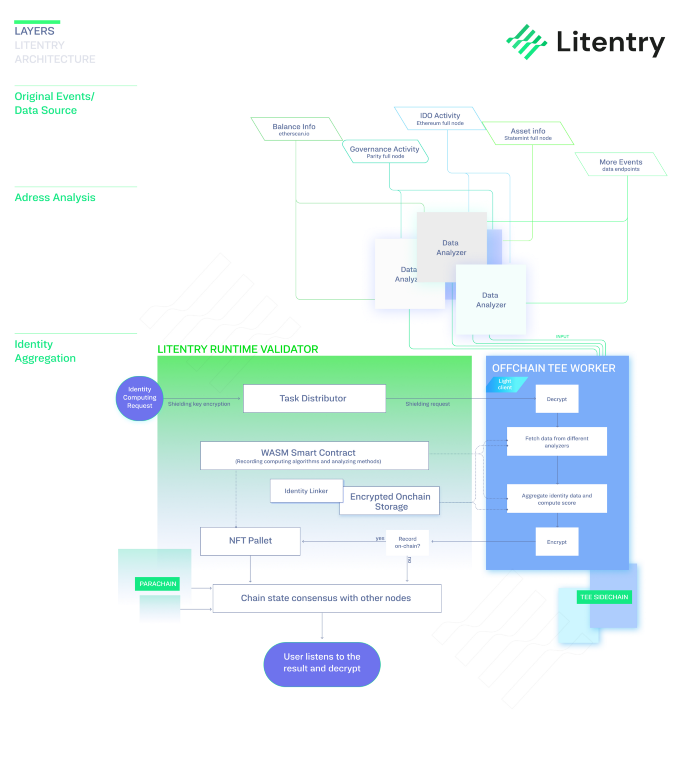
オリジナルイベント/データソースレイヤー
ここでLitentryは、既存のデータレジストリやインデックスサービスに依存してユーザーのオリジナルデータを取得し、データの可用性の提供をEtherscan、The Graph、OnFinalityなどの外部データプロバイダーにオフロードします。
ここでいうオリジナルデータとは、ユーザーが生成し、オープンデータレジストリが記録している既存のデータのことで、特にブロックチェーンが記録している追跡可能で変更不可能なデータ、例えば、チェーンの状態や、過去の取引、放出されたイベントなどを指します。また、オリジナルのIDデータは、Twitter、Facebook、DiscordなどのWeb2.0 APIで提供することもできます。
すべてのデータは、異なるデータエンドポイントから提供される可能性があり、どのデータエンドポイントからデータを取得するかは、データ分析者の選択に委ねられます。
アドレス解析レイヤー
この層は、元のIDデータを処理し、IDアグリゲーションのための分析データを生成します。ID計算サービスは多くのリソースを消費するため、オフチェーンで行い、コンセンサスから分割します。
この層は、ID分析とIDアグリゲーションの計算プロセスを分離します。構造化されたIDデータとコンピューティングリソースの両方に冗長性を持たせることで、計算効率とネットワークスループットを向上させます。
データ分析者
データ分析装置は、Litentry NetworkにID関連のデータ分析サービスを提供する外部ノードです。各データ分析装置は独立して動作し、誠実なID分析結果を提供することで報酬を得ます。Litentry Networkのデータ分析装置の数が多ければ多いほど、アドレス分析層の効率と可用性が高くなります。
仕組み
このレイヤーでは、データ解析者はランダムなタスクを処理して、識別イベントの結果を計算するようにインセンティブを与えられます。識別イベントで指定された分析方法に従い、データアナライザは基本的にデータの索引作業を処理し、シンプルなデータ計算サービスを提供します。
データの整合性
生成されたID関連データは、データの整合性を確保するために各分析装置によって署名され、さらに次のレイヤーで検証されます。1つのタスクは可用性を確保するために常に複数の分析装置で実行されるが、すべての分析装置で実行する必要はない。
アイデンティティ・アグリゲーション・レイヤー
LitentryはIDアグリゲーターとして、信頼性のある正確なIDデータを提供します。そのため、このレイヤーでLitentryネットワークは2つのことを行います。1. 1. アドレス解析レイヤーから解析済みのIDデータを取得し、データの一貫性を証明する。2. クロスプラットフォームのIDデータを集約し、WASMスマートコントラクトから提供されるIdentity Scoring Algorithmに基づいて、Identity Scoreを計算する。このように、アドレスは、Ethereum、Polkadot、BSCなどの異なるネットワークでの過去の活動データに応じて、認定スコアを得ることができます。
アイデンティティ・アグリゲーション・レイヤーは、主に4つの目標を達成します:
- インターオペラビリティ— 任意の ID データの解決
- コンポ―ザビリティ — カスタマイズ可能なID情報の組み合わせとIDスコアの算出
- プライバシー — 権限のない第三者からユーザデータを保護
- セキュリティ — ネットワークの可用性を保証し、攻撃を防ぐ
Litentry RuntimeとTEEサイドチェーンは、IDアグリゲーションサービスのこのような属性を構成しています。
Litentry Runtime
Litentry Runtimeに搭載されている様々なパレットは、相互に連携し、分散型のIDアグリゲーションサービスを実現しており、そのスケーラビリティとセキュリティはSubstrateのフレームワークにより保証されています。Litentry Runtimeには、アカウントリンクやオフチェーンワーカー、スマートコントラクト、アイデンティティなどの主要なパレットが含まれています。
TEE Sidechain
TEE Sidechainは、複数のOCTWで構成されています。これはLitentryメインチェーンにペグするサイドチェーンであり、独自のコンセンサスを持ちます。OCTWはLitentryメインチェーンの集約IDを計算し、ライトクライアントを使ってメインチェーンと同期します。TEE Sidechainは、決定論的なアイデンティティデータを生成し、Litentryメインチェーンは集約されたアイデンティティの結果に合意します。
コアパレット
集約アイデンティティは、分散化された機密性のある信頼できる方法で生成されます。この方法を実現するために、そのような結果を出力するための秩序ある共同作業のために、様々なソフトウェア・パレットが設計されている。以下のセクションでは、Litentrt RuntimeとTEE Sidechainに含まれるパレットを含む、Litentry Protocolのソフトウェアパレットを定義します。これらのパレットは、分散型アグリゲーションIDを生成するためのワークフローに貢献します。
タスク・ ディストリビューター
タスク・ディストリビュータは、外部からのアイデンティティ・コンピューティング・リクエストを処理し、登録されたデータ・アナライザを割り当てるタスクを生成し、データ・アナライザから分析されたアイデンティティ・データを要求して取得するためにOCTWをトリガーします。
ユーザの ID 関係情報の機密性を保つために、ID アグリゲーション・レイヤーのデータ取得および ID 計算プロセスはTEE Sidechainで実行されます。Litentryのタスクディストリビュータは、シールドキーを使用してリクエストを暗号化し、スマートコントラクトIDや乱数などの必要なオンチェーン情報を添えてTEE Sidechainに転送します。
オフチェーンTEEワーカー(OCTW)
LitentryのオフチェーンTEEワーカー(OCTW)は、SubstraTEEフレームワークで構築されています。オフチェーンTEEワーカーはParityのオフチェーンワーカーとは異なり、独自のコンセンサスを持ちながらも、ライトクライアントでLitentry Runtimeと同期し、TEEサイドチェーンを構成します。
TEE(Trusted Execution Environment)とは、セキュリティ機能(隔離実行など)を提供する実行環境のことで、操作ノードや第三者がユーザーデータを閲覧・アクセス・改ざんできない、高度にプライベートなセキュリティ空間のようなものです。LitentryのTEE実装では、計算されたIDとスコアはユーザーの公開鍵で遮蔽されるため、認証された本人以外からは見ることができません。
分析タスクの割り当て
ID計算リクエストの場合、データクエリコマンドとIDスコアリング・アルゴリズムは暗号化されてOCTWに配信されます。OCTWはまず計算要求を復号し、乱数を用いてデータ分析者にタスクを割り当て、その結果を聞きます。
分析結果の検証
OCTWは、異なる分析者から提供された結果を得た後、BFT(ビザンチン・フォールト・トレランス)コンセンサスを用いて決定論的な結果を導き出します。これにより、各ID情報のデータの一貫性が保証されます。このステップでは、ID 所有者の認証の下で要求者が提供したリンクされた ID に従って、個別の ID データが集められます。
IDスコアの計算
具体的なID情報の取得後、OCTWは提供されたIdentity Scoring Algorithm に基づいて ID スコアの計算を開始します。ID スコアは信用の証であると同時に、アプリケーションがスコアに基づいて直接結果を判断できるという、アプリケーション利用の柔軟性をもたらします。
暗号化と結果の出力
最終的にOCTWは、演算データを暗号化した結果をイベントとして出力し、ユーザーはそのイベントを購読して復号化します。出力された結果には平文の署名も含まれており、第三者がその結果がLitentry Networkによって算出されたものであることを証明することができます。
WASMスマートコントラクトパレット
ユーザーはWASMスマートコントラクトでIDコンピューティングリクエストのパラメータを指定することができます。WASMスマートコントラクトはLitentry Networkにスケーラビリティと柔軟性を提供し、Litentry Networkを利用したいと考えている開発者に、分散型のデータ取得やコンピューティングの複雑さを抽象化します。
このパレットは、一連のWASMスマートコントラクトで構成されており、Litentry Networkの知識ベースと識別能力を強化します。主に以下の機能が含まれています:
- データ分析者の登録アイデンティティ情報(公開鍵、API情報、ステーク情報など)の記録
- 外部プロバイダーから提出されたIDスコアリングアルゴリズムの記録
- 識別イベントの分析に使用された識別方法の記録
- カスタマイズされたコンポーザブル ID スコアリング・アルゴリズムの有効化
- 民主主義によるAccount LinkerのIdentity Modelの更新
- XCMPとのスマートコントラクトの交信を有効化
- アイデンティティ・コンピューティング・リクエストの作成の有効化
NFTパレット
Litentry Networkでは、ユーザーのID計算結果を一切保存しませんが、変更頻度の低いデータに対する不要な計算を減らし、IDデータのクエリの効率を高めるために、ユーザーがその結果をNFTとしてオンチェーンで記録することも可能です。NFTパレットはLitentry Networkにおける冗長な計算要求を劇的に削減し、新しい経済モデルを生み出します。
生成
これらのNFTは、Identity Scoring Algorithmsに関連するスマートコントラクトによって生成されます。Litentryブロックチェーンが計算されたIDデータに同意した後、バリデーターが計算結果にNFTコマンドが埋め込まれているかどうかをチェックします。そのような要求があれば、NFTパレットがNFTを作成し、データをオンチェーンで記録します。
ここでは2つのワークフローがあります:
- 能動的な要求:ユーザーがLitentryにID検証の要求を送信し、その結果が真であれば、ユーザーはNFTを取得する
- 受動的要求: 外部の要求者がいくつかの要件を設定し、データ分析者が資格リストを管理し、ユーザーはリストに載った時点でNFTを要求できる
検証可能なクレデンシャル
これらのNFTは、Litentry Networkによって算出された、指定されたID情報の検証可能なクレデンシャルです。ユーザーはこのNFTを使って、第三者に自分の身元を効率的に証明することができます。Litentryは、NFTパレットを通じて、カスタマイズされた検証可能なクレデンシャルを生成するフレームワークを提供します。例えば、dAppの開発者がユーザーのために分散型の認証情報を作成したい場合、dAppの初期の支持者を特定するのに役立ちます。
暗号化されたオンチェーンストレージ
Litentry Networkは、必要なデータのみを保存し、ユーザーが要求しない限り、ユーザーのアイデンティティの計算結果を積極的に保存することはありません。Encrypted On-chain Storageは、Identity LinkerからのユーザーのIDリンク関係データを保存するために使用され、TEEサイドチェーンのシールドキーによって暗号化され、データ漏洩のリスクを排除します。
IDリンカー
IDリンカーパレットは、ユーザのIDリンク関係を書き込むために使用され、IDアグリゲーションプロトコルの基礎となります。OCTWがデータアナライザからIDデータを取得する際には、ターゲットとなるユーザのアドレスを知る必要があります。つまり、ユーザのクロスプラットフォームIDデータを取得するための前提条件は、ユーザの有効なIDリンク関係を知ることです。
アカウント検証
ユーザがアカウント検証要求を開始すると、OCTW は検証プロセスを処理する。ユーザーは、自分の ID 所有権を検証するためのチャレンジを受け取る。例えば、ユーザーが自分のEthereumアカウントをリンクしたい場合、ユーザーは署名を提供する必要があります。TEEのサイドチェーンでは、OCTWが、ユーザーがチャレンジを解決したかどうかを検証します。検証が成功した場合、OCTWはLitentryランタイムにエクストリンシックを送り返し、リンクされたID情報を暗号化されたオンチェーンストレージに保存します。
IDモデル
Identity Linker palletでは、ユーザーはLitentryアドレスとして表現されます。各Litentryアドレスは複数の異なるIDとリンクできます。サポートされている各IDは、特定のプラットフォーム/ブロックチェーンに関連付けられており、最初にサポートされるネットワークには、Bitcoin、Ethereum、Polkadotが含まれます。これは、ネットワークがこれらのネットワークの集約されたID計算をサポートすることを意味します。この場合、プラットフォームごとに異なる識別方法を使用しているため、新しいプラットフォームを追加するには、そのアカウント検証メカニズムの特別な開発が必要になります。新たに追加されたプラットフォーム」に対しては、DAO投票を行う必要があるかもしれません。
プライバシー保護
ID連携プロセスでは、ユーザーのID情報の一部が公開される可能性がありますが、TEEフレームワークでは、検証プロセスにおいてバリデータにユーザー情報が公開されないことを保証しています。これに加えて、ユーザーはアカウントリンク要求を送信する前にOCTWのシールドキーで暗号化する必要があり、送信時のデータセキュリティを確保します。
識別方法
生のブロックチェーンデータを分析してアイデンティティプロファイルを生成する能力は、システム内の識別方法に由来する。Litentryのスコープにおける識別方法(Identification Method)の定義は、未識別のデータを人間が読めるIDデータに変えるために使用する一般的な方法を指します。例えば、クレジットスコアやシンボルバッジのようなものです。Litentry Networkでは、IDデータを計算するために設定可能な関数を使用しており、これには2種類の識別方法-識別イベントとIDスコアリングアルゴリズム-が含まれます。
識別イベント
識別イベント(Identification Event) は、ターゲティングデータに基づいて特定のユーザーの行動を分析し、アイデンティティに関連する情報を出力するよう、データアナライザに指示するコンピューティングコマンドです。
識別イベントは、Litentry Networkの価値を高める重要な要素の一つです。意味のある識別イベントが作成されればされるほど、カスタマイズされたクロスプラットフォームの集約されたアイデンティティを提供する際に、ネットワークはより柔軟性を得ることができます。
ここでは2つのイベントの例を紹介します。どちらもユニークな識別イベントとしてUniswapに対するユーザーのロイヤリティを示すものです:
Event 1
*Pseudocode
Name - Unisocks Edition 0 holders
ID - (Base64 string)
Project Name - Uniswap
Contract - 0x23b608675a2b2fb1890d3abbd85c5775c51691d5
Original Data registry - Ethereum
Analyzing Method - > if(asset balance >0){isOwner = true;} else {isOwner = false; }
Event 1では、ユーザーがUnisocks Edition 0トークンの保有者であるかどうかを分析する方法を記録しています。SOCKSは、Uniswapが発行する限定版の靴下の実物を手に入れる権利を持つトークンです。Unisocks Edition 0を保有しているということは、そのユーザーがUniswapに忠実なユーザーであることを示しています。
Event 2
*Pseudocode
Name - Transaction times with UniswapV2Router02
ID - (Base64 string)
Project Name - Uniswap
Contract - 0x8ad599c3A0ff1De082011EFDDc58f1908eb6e6D8
Original Data registry - Ethereum
Analyzing Method -> {return Interaction times with 0x8ad599c3A0ff1De082011EFDDc58f1908eb6e6D8 of this wallet}
Event 2では、UniswapV2Router02のコンタクトでアドレスが作られたtx回数を計算する方法が記録されています。UniswapV2Router02コントラクトは、Uniswap上のトレーディングプールとのやり取りに使用されるスマートコントラクトです。
アイデンティティ・スコアリングアルゴリズム
アイデンティティ・スコアリングアルゴリズムは、アイデンティティ・スコアの計算に使用され、要求されたIDデータの各部分の重み付け式を指定します。IDスコアリングアルゴリズムはWASMスマートコントラクトを介して公に記録され、異なるリクエスターが再利用することができます。
一般的なアプリケーション層では、アイデンティティ・スコアは、ユーザの信用を反映するための量子化された指標として使用することができます。例えば、Identity EventセクションのEvent 1とEvent 2を組み合わせることで、Uniswap loyal user scoreのシンプルなスコアリングアルゴリズムを作成することができます:
*Pseudocode
Name — Uniswap loyal user score
ID — (Base64 string)
Formular - f(x)= if(Event1_value=true,100,0) +10*Event2_value
このアルゴリズムにより、イベント1とイベント2のスコアを算出する式が作成されます。これによると、イベント1では値が真であれば100点、そうでなければ0点となり、イベント2では、10にイベント2の値をかけたものがスコアとして計算されます。イベント2のスコアは、イベント2の値に10を乗じて算出され、2つのイベントのスコアを加算して合計スコアとなります。
アイデンティティ・スコアは、ユーザの信用や評判、またはアイデンティティを定量化するあらゆる意味を反映することができるものです。コンピュータの著作権に準拠している限り、あらゆるID関連のデータをIDスコアとして計算することができます。Litentry Networkは、このような計算アルゴリズムを記録し、分散化されたIDスコアを処理する機能を提供します。
まとめ
IDアグリゲーションの柔軟性、データの信頼性、コンピューティングの効率性を目的としたLitentryプロトコルは、分散化されたクロスプラットフォームのIDアグリゲーションフレームワークを形成します。Litentry Networkは、識別方法の蓄積に依存しており、反復性があります。ネットワークが識別に関する計算機能を蓄積すればするほど、異なるプラットフォームやdAppsへの識別データの供給が向上します。最終的には、オープンインターネット上のすべてのIDシステムをつなぐIDハブとなるでしょう。